
IP프로토콜
01 네트워크 계층의 기능
- 3 계층의 기본 기능은 송수신 호스트 사이의 패킷 전달 경로를 선택하는 라우팅이다. 라우팅 과정에서 일어나는 문제를 처리하기 위한 기능으로 특정 지역에 트래픽이 몰리는 현상을 다루는 혼잡 제어와 라우터 사이의 패킷 중개 과정에서 다루는 패킷의 분할과 병합이 있다.
라우팅 : 네트워크 구성 형태에 대한 정보는 라우팅 테이블이라는 기억 장소에 보관되고 이 정보를 이용해 패킷이 목적지까지 도달하기 위한 경로를 선택하는데 이 과정을 라우팅(Routing)이라 한다.
혼잡 제어 : 네트워크에 패킷 수가 과도하게 증가하는 현상(Congestion)을 예방하거나 제거하는 기능으로 네트워크 전체 속도를 관리해야 한다.
패킷의 분할과 병합 : 상위 전송 계층에서 송신을 요구한 데이터는 최종적으로 MAC 계층의 프레임 구조에 정의된 형식으로 캡슐화되어 물리적으로 전송된다. 4 계층에서 보낸 데이터가 너무 크면 여러 개의 패킷으로 쪼개서 전송하는 과정을 패킷 분할(Segmentation)이라 하고, 목적지에서 분할된 패킷을 다시 모으는 과정을 병합(Reassembly)이라 한다.
1. 연결형 서비스와 비연결형 서비스
- 3 계층이 4 계층에 제공하는 서비스는 송수신 호스트 사이에 연결을 설정하는 연결형, 연결 설정 없이 데이터를 패킷 단위로 전송하는 비연결형이 있다.

1.1 비연결형 서비스
(Connectionless Service) : 패킷의 전달 순서, 패킷 분실 여부 등에서 연결형 서비스보다 신뢰성이 떨어지는 전송 방식으로 4 계층에서 3 계층의 비연결형 서비스를 이용할 때 연결형 서비스를 이용하는 경우보다 자체적으로 오류 제어와 흐름 제어 기능을 더 많이 수행해야 한다.
- 비연결형 서비스는 패킷이 서로 다른 경로를 통해 목적지 호스트로 전달되기 때문에 도착하는 순서가 일정하지 않아서 이를 수신하는 4 계층은 패킷의 순서를 재조정하는 기능이 필요하다.
1.2 연결형 서비스
(Coneection-oriented Service) : 신뢰성이 높은 서비스로 연결을 미리 설정하여 송신하는 방식이다.
2. 라우팅
- 가상 회선을 사용하는 연결형 서비스에서 송수신 호스트 사이의 경로 선택은 연결이 설정되는 시점에 한 번만 결정하고, 이후의 패킷들은 이 경로를 따라 목적지까지 전달된다. 따라서 가상 회선 방식에서는 전송되는 모든 패킷이 동일 경로를 거치고 패킷의 전달 순서도 일정하게 유지된다.
- 비연결형 방식의 데이터그램을 사용하면 연결 설정 과정이 없기 때문에 송수신 호스트 사이에 고정 경로가 조재하지 않아 독립적인 전달 경로를 선택해야 한다.
2.1 정적/동적 라우팅
정적 라우팅(Static Routing)
: 송수신 호스트 사이에서 패킷 전송이 이뤄지기 전에 경로 정보를 라우터에 미리 저장하여 중개하는 방식이다.
- 패킷을 중개하기 위한 최적의 경로 정보는 라우터 별로 저장하여 관리하는데, 정적 라우팅은 운용 중인 네트워크의 구성에 정보를 갱신하기 쉽지 않으며, 특히 네트워크 내부의 혼잡도를 반영할 수 없다는 문제가 있다.
동적 라우팅(Dynamic Routing)
: 라우터에서 사용하는 경로 정보를 네트워크 상황에 따라 적절하게 변경하는 방식으로, 경로 정보의 변경 주기에 따라 보완할 수 있고 현재의 네트워크 상황을 고려해 최적의 경로 정보를 선택할 수 있지만, 경로 정보를 수집하고 관리하는 등의 복작한 작업이 추가로 필요해 네트워크 성능에 영향을 미치는 문제가 있다.
- 동적 라우팅 방식을 사용하려면 현재 네트워크 링크 상태를 점검해 이를 새로운 경로 배정 시 적용해야 한다. 우선 각 라우터에서 이웃 라우터의 존재 유무와 전송 지연 시간 등을 확인할 수 있어야 하며 경로 정보를 다른 라우터들에 통보해서 최신 경로 정보를 공유 및 갱신해야 한다.
2.2 HELLO/ECHO 패킷
- 라우터의 초기화 과정에서 가장 먼저 할 일은 이웃 라우터의 경로 정보를 파악하는 것이다. 각 라우터는 이웃에 연결된 라우터에 초기화를 위한 HELLO 패킷을 전송해 경로 정보를 얻는다.
- 라우터 사이의 전송 지연 시간을 측정하기 위해서 ECHO 패킷을 전송하는데, ECHO 패킷을 수신한 호스트는 송신 호스트에 즉각 회신하도록 설계되어 있다. 이런 과정을 반복하고, 측정값의 평균을 구해 해당 라우터까지의 전송 지연 시간을 유추할 수 있다.
2.3 라우팅 테이블
- 패킷 전송 과정에서 라우터들이 적절한 경로를 쉽게 찾도록 하기 위한 가장 기본적인 도구로 라우팅 테이블을 사용
- 라우팅 테이블에 포함해야 하는 필수 정보 - [목적지 호스트, 다음홉]
'목적지 호스트'에는 패킷의 최종 목적지가 되는 호스트의 주소 값을, '다음 홉'에는 목적지 호스트까지 패킷을 전달하기 위한 이웃 라우터를 지정.
-> 목적지까지 도달하는 여러 경로 중에서 효과적인 라우팅을 지원하는 경로가 있는데 이 경로에 다음 홉에 위치한 라우터의 주소를 기록한다.
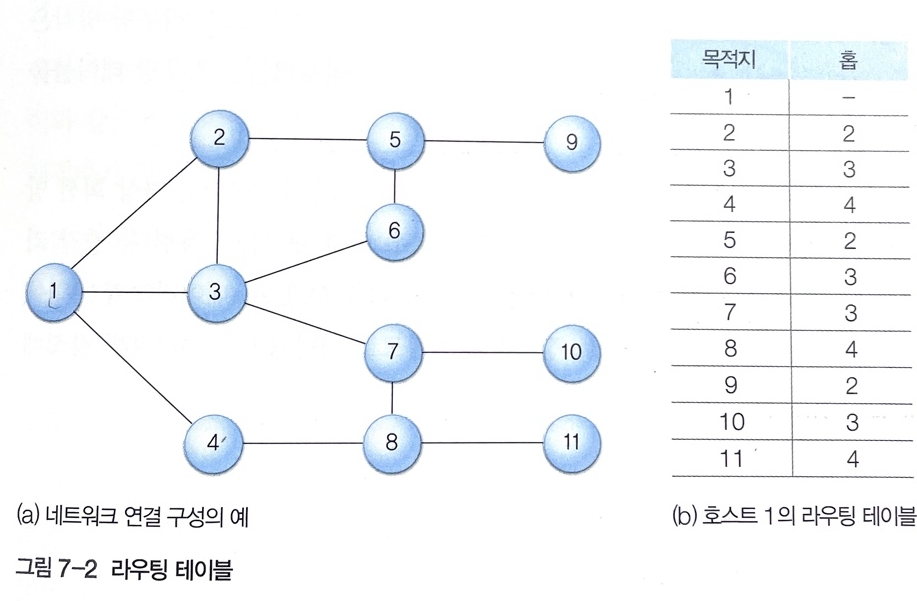
ex) 호스트 1 --> 호스트 11의 패킷 경로 선택 과정
호스트 11의 다음 홉 값이 4번 라우터로 되어 있으므로 호스트 1은 패킷을 4번으로 전송.
다시 자신의 라우팅 테이블 정보를 이용해 전송 경로에 있는 다음 홉의 호스트에 패킷을 전달하고 최적 목적지에 도착할 때까지 반복한다.
2.4 라우팅 정보의 처리
- 라우팅을 효과적으로 수행하기 위해 네트워크의 현재 상황을 반영하도록 관리하는 방법으로 소스, 분산, 중앙, 계층 라우팅이 있다.
소스 라우팅(Source Routing)
: 패킷을 전송하는 호스트가 목적지 호스트까지 전달 경로를 스스로 결정하는 방식으로 소스 라우팅을 지원하려면 송신 호스트의 라우팅 테이블에서 패킷을 패킷을 수신 호스트까지 전달하기 위한 경로 정보를 관리해야 하며 경로 정보를 전송 패킷에 기록해야 한다.
- 중간 라우터에서는 전송 패킷에 포함된 경로 정보를 이용해 패킷을 중개함으로써 최종 목적지까지 올바르게 전달할 수 있다.
- 데이터그램과 가상 회선 방식 모두 이용 가능하며 가상 회선 방식에선 연결의 초기화 과정에서 경로 정보를 담은 특수 연결 패킷을 사용하고 중간 라우터는 패킷의 경로 정보를 해석함으로써 전달 경로를 선택할 수 있다.
- 데이터그램 방식에선 전송되는 모든 패킷의 헤더에 경로 정보가 들어가 일반적인 데이터그램 방식에 비해 신뢰성을 향상할 수 있다.
분산 라우팅(Distributed Routing)
: 라우팅 정보가 분산되는 방식으로 패킷의 전송 경로에 위치한 각 라우터가 효율적인 경로 선택에 참여한다.
- 데이터그램 방식에서 많이 사용하며 네트워크에 존재하는 호스트의 수가 많아질수록 다른 방식보다 효과적일 수 있다는 장점이 있다.
중앙 라우팅(Centralized Routing)
: RCC(Routing Control Center)라는 특별한 호스트를 사용해 전송 경로에 관한 모든 정보를 관리하는 방식이다.
- 패킷 전송을 원하는 송신 호스트는 반드시 RCC로부터 목적지 호스트까지 도착하기 위한 경로 정보를 미리 얻어야 하며 이정보를 이용해 송신 호스트는 소스 라우팅과 동일한 원리로 패킷을 전송한다.
- 경로 정보를 특정 호스트가 관리하기 때문에 다른 일반 호스트가 경로 정보를 관리하는 부담을 줄일 수 있지만 네트워크의 규모가 커지면 RCC에 과중한 트래픽을 주어 전체 효율이 떨어질 수 있다.
계층 라우팅(Hierarchical Routing)
: 분산 라우팅 기능과 중앙 라우팅 기능을 적절히 조합하는 방식으로 전체 네트워크 구성을 계층 구조 형태로 관리함 네트워크 규모가 계속 커지는 환경에 효과적이다.
3. 혼잡 제어
- 흐름 제어(Flow Control)는 송수신 호스트 사이의 논리적인 점대점 전송 속도를 다루는 반면 혼잡 제어(Congestion Control)는 더 넓은 관점에서 호스트와 라우터를 포함한 서브넷에서 네트워크의 전송 능력 문제를 다룬다.
- 혼잡의 주요인인 네트워크의 처리 능력보다 지나치게 많은 패킷이 입력될 때로 개별 라우터 관점에서 보면 라우터의 출력 선로를 통한 전송 용량이 부족해 아직 전송하지 못한 패킷이 버퍼에 저장되고, 입력 선로로 들어오는 패킷이 늘면서 버퍼 용량이 부족해진다.
결과적으로 라우터의 내부 버퍼 용량 부족이 심화되어 패킷을 보관할 수 없어 버리게 된다. 그러면 송신 호스트가 타임아웃 동작을 통해 패킷을 재전송하므로 네트워크로 송신되는 패킷의 양이 늘어난다.
->라우터에서 패킷을 잃지 않으려면 버퍼 용량을 늘려야 하는데 늘리면 패킷 전송 지연시간도 늘어난다.
[전송 지연 시간] > [타임아웃 시간] => 재전송 과정이 증가할 수 있어 네트워크로 보내지는 패킷의 양과 중복 패킷을 수신하는 현상도 증가하여 네트워크 혼잡도가 계속 증가하는 악순환 발생.
(버퍼 용량↑, 전송 지연시간 ↑, 재전송 과정↑, 수신 호스트가 중복 수신량↑, 네트워크 혼잡도↑)
3.1 혼잡의 원인
위에서 설명한 전송 시간 초과에 의한 타임아웃 기능을 통해 패킷들의 재전송
패킷의 도착 순서가 뒤바뀔 때 수신 호스트는 패킷을 보관하거나 그냥 버리는데, 버릴 때 재전송 현상이 발생해 혼잡을 높인다.
패킷이 제대로 수신되었는지를 송신 호스트에 알려주는 응답 알고리즘도 혼잡에 영향을 준다.
- 수신한 패킷들에 대해 즉시 응답하는 방식을 사용하면 수신 패킷 모두에 대하여 개별 응답 패킷이 발생한다. 수신한 패킷들에 대해 즉시 응답하는 방식을 사용하면 수신 패킷 모두에 대하여 개별 응답 패킷이 발생해 패킷 여러 개를 모아 하나의 응답으로 처리하는 방식이나 피기 배킹을 사용하는 방식과 비교하면 혼잡도에 미치는 영향이 다르다.
라우팅 알고리즘
- 혼잡이 발생되고 있는 경로보다는 전송 트래픽이 적은 경로를 찾아 패킷을 전송하면 혼잡도를 줄일 수 있다.
- 네트워크에서 전송 중인 패킷은 수신 호스트에 도착할 때까지 목적지를 향해 무한정 라우팅 되지는 않는다.
패킷 별로 네트워크에 존재할 수 있는 일정한 생존 시간을 지정해 이 시간을 넘지 않도록 각 라우터를 통과할 때마다 홉(Hop) 수를 증가시켜 일정한 개수 이상의 라우터를 통과하면 엉뚱한 경로를 떠도는 것으로 판단해 해당 패킷을 네트워크에서 제거한다.
3.2 트래픽 성형
- 혼잡은 트래픽이 특정 시간에 집중되는 버스트(Burst) 현상에서 기인하는 경우가 많아 송신 호스트에서 전송하는 패킷이 짧은 시간 동안 많이 발생하는 경우에 혼잡이 일어날 확률이 높기 때문에 송신 호스트가 전송하는 패킷의 발생 빈도가 네트워크에서 예측할 수 있는 전송률로 이뤄지게 하는 기능인 트래픽 성형(Traffic Shaping)이 필요하다.
- 송신 호스트는 사전에 네트워크와 협상하여 네트워크로 유입되는 패킷의 특성을 조율할 수 있다. 협상을 통해 네트워크로 유입되는 패킷의 분포 특성을 미리 정해두면 네트워크에서는 전체 트래픽의 혼잡도를 예측하여 혼잡 제어를 효율적으로 수행할 수 있다.
- 송신 호스트가 사전에 약속한 트래픽보다 과도한 양의 패킷을 전송하면 네트워크에서 적절히 통제해야 하는데 네트워크에서 처리하기에 과도한 트래픽이 발생하면 협상 내용의 위반 정도에 따라 패킷 처리를 거부할 수 있다.
이와 같은 트래픽 성형과 관련된 알고리즘으로 리키 버킷(Leaky Bucket)이 있다.
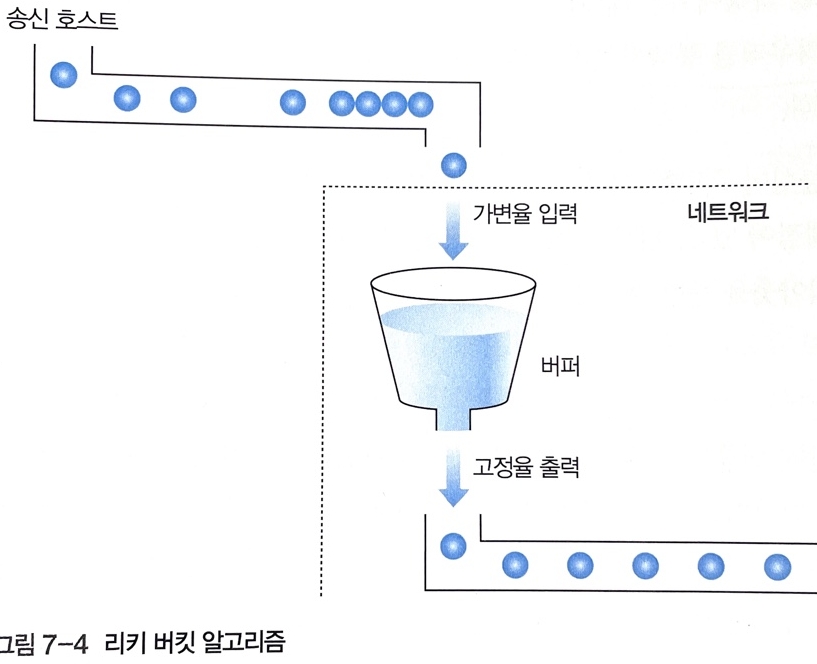
--> 송신 호스트와 네트워크 사이에는 송신 호스트가 협상에서 제시한 전송 특성을 반영하는 적절한 크기의 깔때기가 위치한다. 깔때기의 출구 크기는 협상 결과를 의미하며 크기가 고정되어 있다.
따라서 송신 호스트가 협상 값보다 많은 양의 패킷을 전송해도 깔때기 크기 이상의 패킷이 네트워크에 유입될 수 없어 과도하게 입력된 패킷은 깔때기의 부피 범위 내에서 내부 버퍼에 임시 저장된다. (한계치 초과 시 패킷 분실 오류 발생)
3.3 혼잡 제거
혼잡 처리 방법 3가지
혼잡이 사라질 때까지 연결 설정을 허락하지 않는 것
가상 회선 방식을 사용하는 서브넷에서 혼잡을 감지했을 때 이를 완화하는 가장 간단한 방법 중 하나는 혼잡이 사라질 때까지 연결 설정을 허락하지 않는 것이지만 네트워크 전체보다 일부 지점에서 혼잡 발생이 많다.
따라서 특정 지역에 혼잡이 발생하면 패킷의 전송 경로를 적절히 조정해줌으로써 혼잡이 발생한 곳을 거치지 않도록 가상 회선 연결을 설정하는 방안이 필요.
호스트와 서브넷이 가상 회선 연결 과정에서 협상하는 것
- 사용하는 대역을 미리 할당 받음으로써 네트워크에서 수용 불가능한 정도로 트래픽이 발생하는 일을 사전에 예방하는 것.
문제는 개별 연결이 예약한 전송 대역을 해당 사용자가 이용하지 않더라도 다른 사용자가 이용하지 못한다는 점으로 이러한 자원 예약(Resource Reservation) 방식은 통신 자원을 낭비할 수 있다.
ECN(Explicit Congestion Notification) 패킷을 사용하는 것
- 라우터는 자신의 출력 선로 방향으로 전송되는 트래픽의 양을 모니터 할 수 있어 출력 선로의 사용 정도가 한계치를 초과하면 주의 포시를 해두고 주의 표시한 방향의 경로는 혼잡이 발생할 가능성이 높아 특별 관리한다.
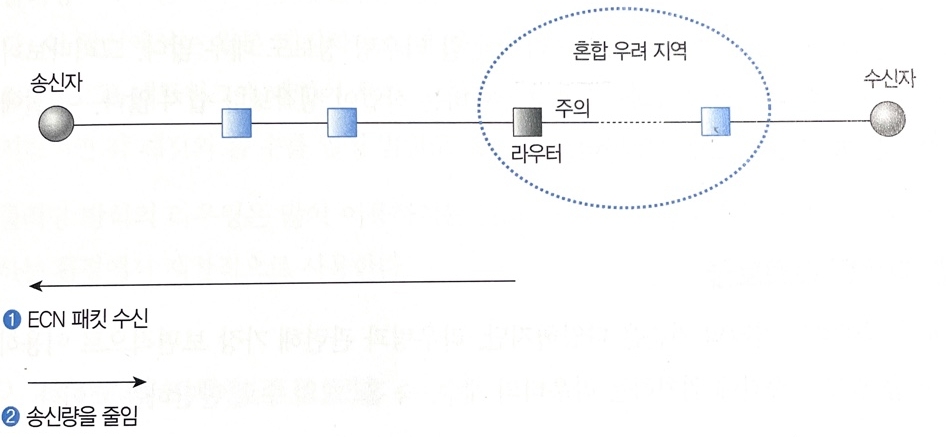
(1) - 혼잡 지역에 위치한 라우터는 입력 선로로 들어온 패킷이 주의 표시된 출력 선로로 라우팅 되는 경우에 패킷의 송신 호스트에 ECN 패킷을 전송
(2) - ECN 패킷을 수신한 송신 호스트는 데이터 패킷이 전송되는 경로에서 혼잡이 발생할 가능성이 있음을 인지하였으므로 전송 패킷의 양을 줄인다.
- 특정 라우터에서 주의 포시를 시작하면 이후 경로에 위치한 라우터에도 주의 표시할 가능성이 높고 ECN 패킷이 여러 라우터에서 동시에 발생할 가능성이 높다.
따라서 최초로 ECN 패킷을 발생시킨 라우터에서는 전송되는 패킷의 헤더 내부에 ECN-Echo와 같은 임의의 표시를 하여 목적지까지 도착하는 동안에 거치는 라우터가 ECN 패킷을 더 이상 발생하지 않도록 해야 한다.
02 라우팅 프로토콜
1. 간단한 라우팅 프로토콜
- 네트워크에서 거리의 기준으로 라우터의 개수인 홉(Hop)의 수로 판단한다.
1.1 최단 경로 라우팅
: 패킷이 목적지에 도달할 때까지 거치는 라우터 수가 최소화될 수 있도록 경로를 선택한다.
- 비교적 간단하며 쉽게 적용하며 패킷이 목적지까지 도착하는 여러 경로 중 가장 짧은 경로를 선택한다.
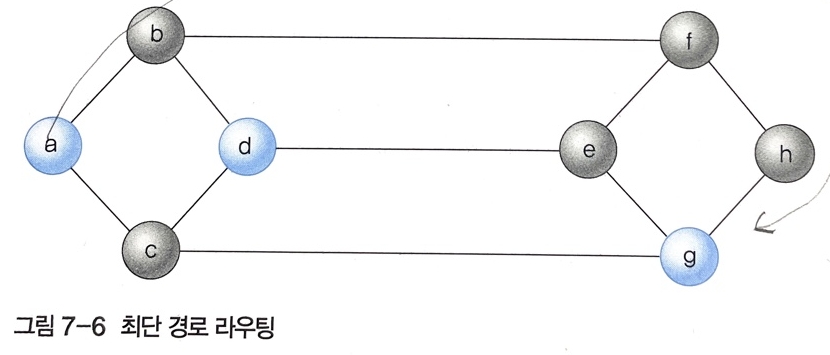
-> a->g까지의 경로가 여러 개이지만 가장 짧은 경로 라우터 C만 거친다
1.2 플러딩
(Flooding) : 라운터가 자신에게 입력된 패킷을 출력 가능한 모든 경로로 중개하는 방식으로 원본 패킷과 동일한 패킷이 무수히 생성되고, 모든 경로를 통해 반복하여 전송하므로 네트워크에 패킷이 무한 개 만들어질 수 있다.
무한정 증가하는 현상을 방지하려면 각 패킷의 홉 수를 일정 범위로 제한해 라우터에서 이를 확인하여 제거해야 한다.
2. 거리 벡터 라우팅 프로토콜
(Distance Vector) : 라우터가 자신과 직접 연결된 이웃 라우터와 라우팅 정보를 교환하는 방식이다. 정보를 교환하는 라우터는 거리 벡터 프로토콜을 사용하는 호스트나 라우터로 교환 정보는 각각의 라우터에서 전체 네트워크에 소속되는 개별 네트워크까지 패킷을 전송하는 데 걸리는 거리 정보다.
- 거리 벡터 알고리즘 구현에 필요한 관리
링크 벡터 : 이웃 네트워크에 대한 연결 정보
거리 벡터 : 개별 네트워크까지의 거리 정보
다음 홉 벡터 : 개별 네트워크로 가기 위한 다음 홉 정보
2.1 링크 벡터 L(x)
- 링크 벡터 L(x)는 라우터 x와 직접 연결된 이웃 네트워크에 대한 연결 정보를 보관한다. 라우터 x와 직접 연결된 네트워크가 M개일 때 -> L(x) = [포트 1, 포트 2,..., 포트(M)]
- 링크 벡터에 보관된 정보는 라우터 x가 해당 네트워크와 연결하기 위해 할당한 라우터 포트 번호다.
- R1의 링크 벡터 정보를 구하려면 연결된 네트워크가 뭔지 알아야 한다.(Net1, Net2)로 밑의 정보와 같다.
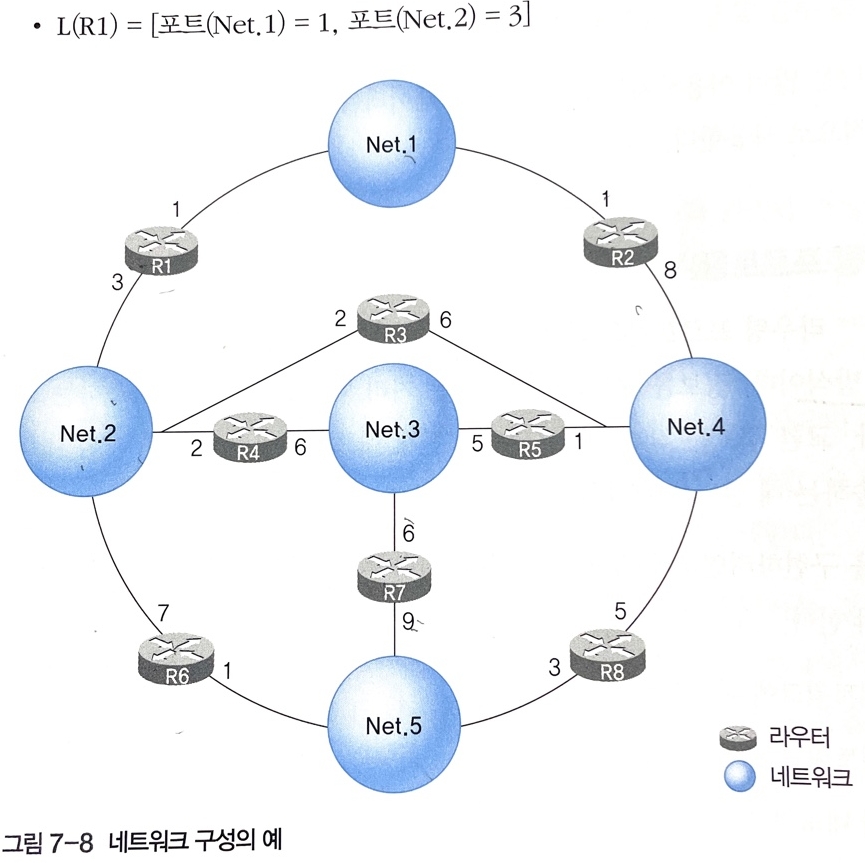
- 라우터 R2와 R7도 동일한 원리로 정보를 구하고 링크 벡터는 자신과 직접 연결된 이웃 라우터가 누군지 판단하기 위한 자료이다.
2.2 거리 벡터 D(x)
- D(x)는 전체 네트워크에 소속된 개별 네트워크들까지의 거리 정보를 관리한다. 네트워크가 N개일 때
-> D(x) = [거리 1, 거리 2,..., 거리(N)]
- 거리 벡터에서 관리하는 정보는 일반적으로 개별 네트워크까지 패킷을 전송하는 데 걸리는 최소 전송 지연 시간이다.
ex) 위 그림의 R1을 위한 거리 벡터 값은
D(x) = [거리(Net.1) = 1, 거리(Net.2) = 1, 거리(Net.3) = 2, 거리(Net.4) = 2, 거리(Net.5) = 2]이며 전체 네트워크에 포함된 네트워크는 5개이므로 보관 값도 5개이다.
2.3 다음 홉 벡터 H(x)
: H(x)는 개별 네트워크까지 패킷을 전송하는 경로에 있는 다음 홉 정보를 관리한다.
-> H(x) = [홉 1, 홉 2,..., 홉(N)]
2.4 RIP 프로토콜
(Routing Information Protocol) : 거리 벡터 방식을 사용하는 내부 라우팅 프로토콜 중에서 가장 간단하게 구현된 것으로 소규모 네트워크 환경에 적합하며, 동작하기 위해 거리 벡터 정보가 임의의 짧은 시간 내에 모두 도착해야 하지만 구현이 쉽지 않다.(UDP로 전송 과정에서 패킷이 사라질 수도 있다)
-이런 이유로 제한을 두어 라우팅 테이블에 순차적으로 적용되게 한다.(첫 번째 두 번째는 자신이 관리하는 거리 벡터 정보이고 세 번째는 다른 라우터로부터 받는 거리 벡터 정보)
입력되는 거리 벡터 정보가 새로운 네트워크의 목적지 주소이며 라우팅 테이블에 적용한다.
입력되는 거리 벡터 정보가 기존 정보와 비교하여 목적지까지 도착하는 지연이 더 적으면 대체한다. 즉 이전 정보와 홉 수가 같아도 추가 지연 측정을 통해 지연시간이 적으면 새로운 경로를 선택한다.
임의의 라우터로부터 거리 벡터 정보가 들어왔을 때, 라우팅 테이블에 해당 라우터를 다음 홉으로 하는 등록 정보가 있으면 새로운 정보로 수정한다.
ex) 라우터 R1과 직접 연결된 주변 라우터로부터 라우팅 정보가 주기적으로 입력된다. 임의의 시점에 다음의 거리 벡터 정보가 들어온다면
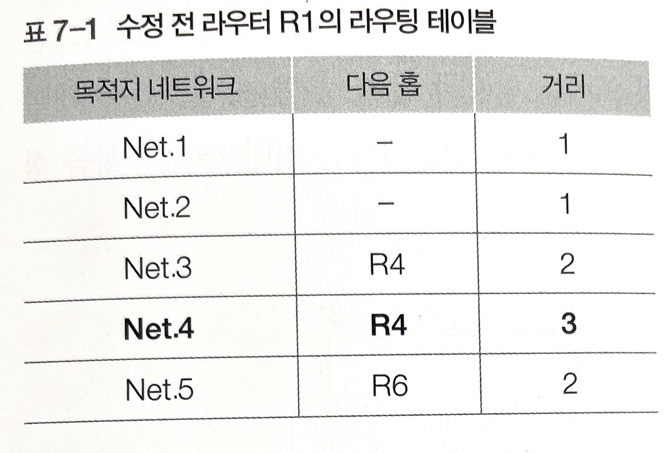
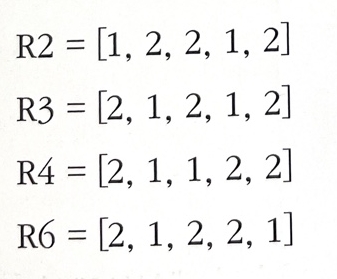
-> 각 값은 순서대로 Net.1부터 Net.5까지의 거리이다.
네트워크 Net.4로 갈 때 라우터 R4나 R6를 거치면 거리가 2지만 라우터 R2나 R3를 거치면 1이다. 이중 짧은 거리를 선택하고 이는 라우팅 테이블에 반영한다.
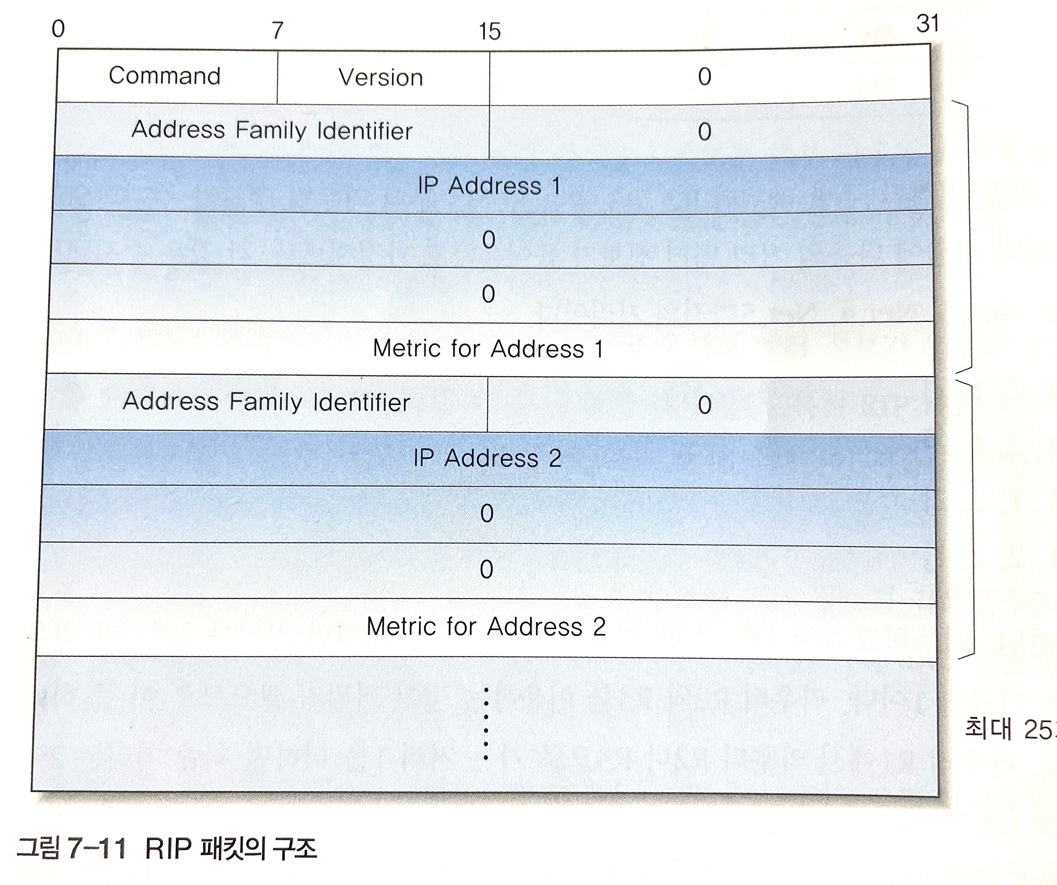
-> RIP는 라우터 사이에서 링크 벡터, 거리 벡터, 다음 홉 벡터 등의 정보를 교환하려고 위와 같은 패킷 구조를 사용한다.
Command(명령) : 값이 1이면 RIP 요청을, 2면 RIP 응답을 의미.
Version : 버전 번호
Address Family Identifier(주소 패밀리 구분자) : IP 프로토콜의 주소는 2로 설정된다
IP Address(IP 주소) : 특정한 네트워크를 지칭하는 용도로 사용
Metric(거리) : 해당 라우터에서 목적지 네트워크까지의 거리다.
3. 링크 상태 라우팅 프로토콜
: 링크 상태(Link State) 라우팅 프로토콜은 라우터 간의 정보 교환 원리가 거리 벡터 방식과 반대로 개별 라우터가 이웃 라우터까지의 거리 정보를 구한 후, 이를 네트워크에 연결된 모든 라우터에 통보한다.
- 거리 벡터의 단점인 각 라우터가 상당한 양의 정보 전송을 요구받고, 상태가 많이 변하면 시간이 많이 걸리는 단점을 극복하려 고안됐다.
거리 벡터 라우팅은 알고리즘 특성상 정보가 주기적으로 전달되지만 링크 상태 라우팅은 이웃 라우터와 연결돼 상황에 변화가 있을 때만 정보 전달이 이뤄지며 정보 전달을 위해 플러딩 기법을 사용한다.
임의의 라우터가 이웃한 모든 라우터에 정보를 전달하고, 다시 이들 라우터가 주변의 모든 라우터에 정보를 전달하는 방식으로 동작한다.
- TCP/IP 기반의 인터넷에서 사용하는 OSPF(Open Shortest Path First)가 있다. [내부 라우팅]
4. 외부 라우팅 프로토콜
: 경로 벡터(Path Vector) 프로토콜을 사용하며 경로에 관한 거리 정보 값이 필요 없는 방식이다.
단순히 해당 라우터에서 어느 네트워크가 연결 가능한지에 대한 정보만을 제공한다. (원거리)
- 거리 벡터와의 차이
거리에 대한 처리 과정이 이뤄지지 않는다
관리하는 라우팅 정보에는 목적지 네트워크에 도착하기 위한 자율 시스템에 관한 내용만 포함한다.
-종류로 BGP(Border Gateway Protocol)는 외부 라우팅 프로토콜로 서로 다른 종류의 자율 시스템에서 동작하는 라우터가 라우팅 정보를 교환할 수 있도록 해준다. 이와 같이 종류가 다른 환경에서 동작하는 라우터를 일반적으로 게이트웨이라 한다.
BGP는 TCP 프로토콜을 이용해 메시지를 교환한다.
Open - 다른 라우터와 연관을 설정
Update - 라우팅 관련 정보를 전달
KeepAlive - Open 메시지에 대한 응답 기능과 주변 라우터와의 연관을 주기적으로 확인
Notification - 오류 상태를 통보
03 IP 프로토콜
-IP 프로토콜의 주요 특징
비연결형 서비스를 제공
패킷을 분할/병합하는 기능을 수행
데이터 체크섬은 제공하지 않고 헤더 체크섬만 제공
Best Effort 원칙에 따른 전송 기능 제공
1. IP 헤더 구조
- DS + ECN 필드로 우선순위, 지연, 전송률, 신뢰성 등의 값을 지정.(QoS와 관련)

1.1 DS/ECN(Differentiated Services/Explicit Congestion Notification)

- DS를 사용하기 위해 사전에 서비스 제공자와 서비스 이용자 사이에 서비스 등급에 대한 합의가 라우터에 의해 이뤄지며 ECN 필드 값의 의미는

- 송신 호스트가 라우터에게 IP 패킷에 캡슐화된 TCP 프로토콜이 ECN 기능을 지원한다고 알려주기 위해 사용.
- DS 코드 포인트라고도 하는 DS 필드 값은 차등 서비스의 기준이 되는 레이블 값으로 64개의 트래픽 클래스를 정의한다.
1.2 패킷 분할
- IP 프로토콜은 상위 계층에서 내려온 전송 데이터가 패킷 하나로 전송하기에 너무 크면 분할해서 전송하는 기능을 제공
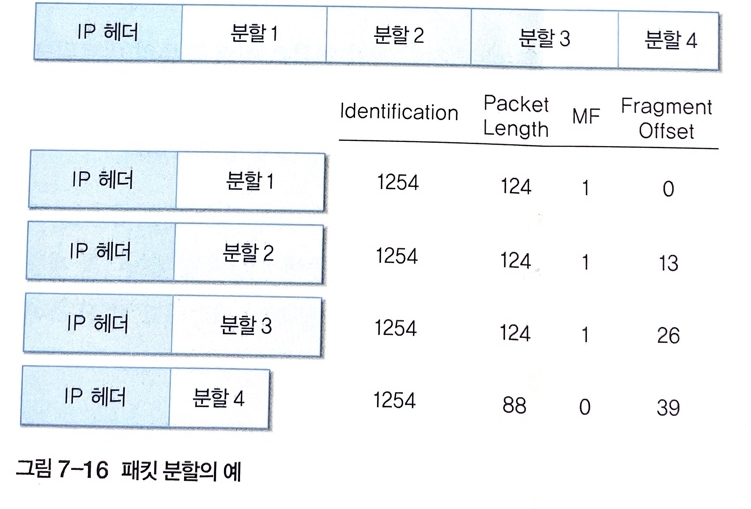
Identification(식별자 혹은 구분자) : IP 헤더의 두 번째 워드에는 패킷 분할과 관련된 정보가 포함해 송신 호스트가 지정하는 패킷 구분자 기능을 수행. IP 프로토콜이 분할한 패킷에 고유 번호를 붙여 다시 병합하도록 해준다.
DF(Don't Fragment) : 패킷이 분할되지 않도록 한다. (1이면 분할을 막는다.)
MF(More Fragment) : 분할된 패킷을 전송할 때 여러 개의 분할 패킷이 연속해서 전송되므로 필드 값을 1로 지정해 분할 패킷이 뒤에 계속됨을 표시해줘야 한다. 0 은 분할 패킷이 더 없음
FragmentOffset(분할 옵션) : 패킷 분할이 이뤄지면 12비트의 필드를 사용
1.3 주소 관련 필드
- Source Address는 송신 호스트의 IP주소이고, Destination Address는 수신 호스트의 IP주소이다.
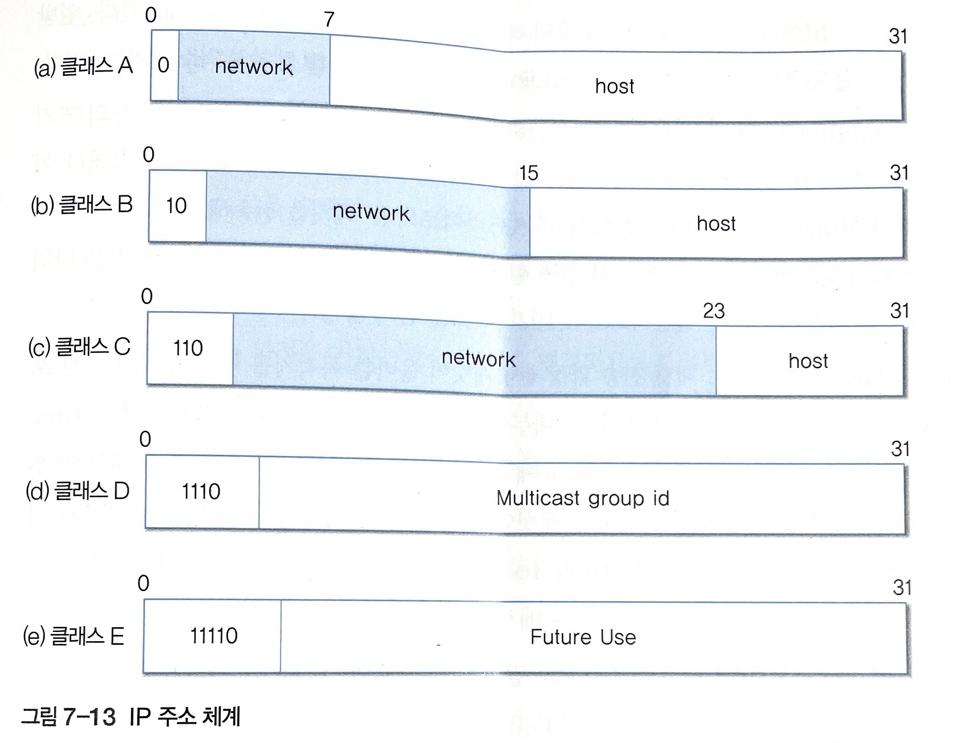
IP 주소 체계는 5개로 A, B, C는 유니캐스팅에서 이용하고 D는 멀티캐스팅에서 E는 후에 사용될 예약된 클래스이다.
A,B,C는 network와 host로 구분되며
network : 네트워크 주소로 유일한 번호가 모든 컴퓨터 네트워크에 할당. NIC(Network Information Center)가 담당
host : 네트워크 주소가 결정되면 하위의 호스트 주소를 의미하는 비트 값을 개별 네트워크의 관리자가 할당한다.

1.4 기타 필드
Version Number(버전 번호)
Header Length(헤더 길이)
Packet Length(패킷 길이)
Time to Live(생존 시간)
Trasport(전송 프로토콜) : 전송 계층의 프로토콜을 가리키며 TCP 세그먼트와 UDP 데이터그램, 네트워크 계층의 ICMP 패킷은 모두 IP 패킷의 데이터를 의미하는 페이로드 부분에 캡슐화되어 전송.
Header Checksum(체크섬)
Options(옵션)
Padding(패딩)
2. 패킷 분할
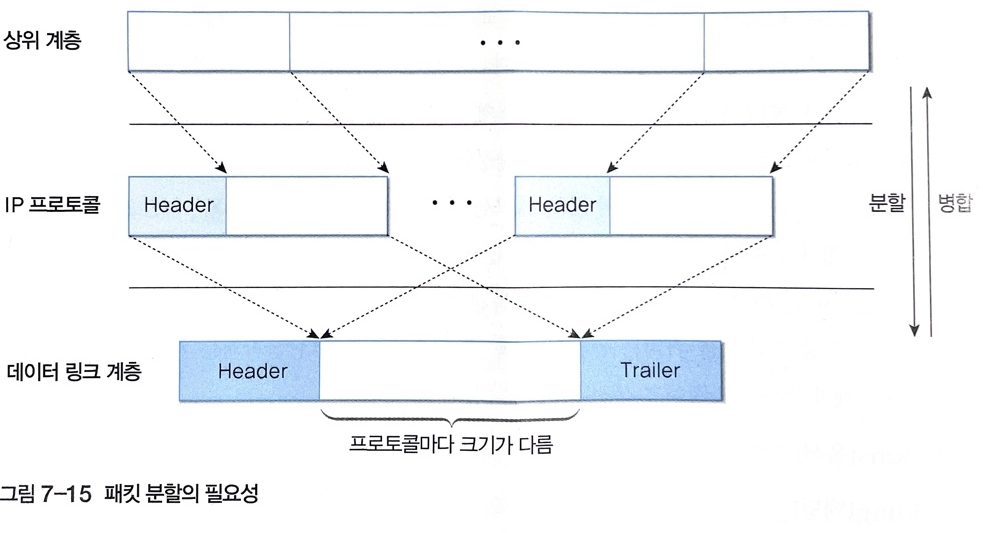
- 다양한 유형의 네트워크를 통해 패킷을 중개하려면 처리하기 편한 크기로 분할해야 한다.
2.1 분할의 필요성
- TCP에서 설정되는 논리적인 가상 연결은 여러 종류의 네트워크를 거쳐서 설정되지만 TCP 프로토콜은 패킷 전송 과정에 위치하는 네트워크 유형에 따라 패킷 크기를 조절하기가 쉽지 않아 IP 프로토콜에서 분할을 해야 한다.(라우터에서 수행)
2.2 분할의 예
3. DHCP 프로토콜
- 특정 네트워크를 관리하는 네트워크 관리자는 개별 호스트들에 수동으로 고정 IP 주소를 할당할 수 있지만 IP 부족으로 DHCP(Dynamic Host Configuration Protocol)를 사용해 자동으로 할당한다.(풀에 저장되며 IP 주소 요청이 오면 풀에서 하나의 IP 주소를 할당)
3.1 DHCP 메시지

Last updated