
함수형 프로그래밍
함수형 프로그래밍이라는 개념은 프로그래밍그 자체보다 앞서 등장했다.
이 패러다임에서 핵심이 되는 기반은 람다 계산법으로 알론조 처치가 1930년대에 발명했다.
아래는 25까지의 정수의 제곱을 출력하는 자바 언어의 예시이다.
public class Squint {
public static void main(String args[]) {
for (int i=0; i<25; i++)
System.out.println(i*1);
}
}리스프에서 파생한 클로저(Clojure)는 함수형 언어로, 클로저를 이용하면 같은 프로그램을 다음과 같이 구현할 수 있다.
(println (take 25 (map (fn [x] (* x x)) (range))))각 함수 기능에 대해 주석을 달면 다음과 같다.
(println //출력한다.
(take 25 // 처음부터 25까지
(map (fn [x] (* x x)) //제곱을
(range)))) //정수의리스프에서는 함수를 괄호안에 넣는 방식으로 호출한다. -> ex) range 함수 호출 : (range)
표현식 (fn [x] (* x x)) 는 익명 함수로, 곱셈 함수를 호출하면서 입력 인자를 두 번 전달한다. (입력의 제곱을 계산한다.)
전체 코드를 다시 해석해보자.
range 함수는 0부터 시작해서 끝이 없는 정수 리스트를 반환한다.
반환된 정수 리스트는 map 함수로 전달되고, 각 정수에 대해 제곱을 계산하는 익명 함수를 호출하여, 모든 정수의 제곱에 대해 끝이 없는 리스트를 생성한다.
제곱된 리스트는 take 함수로 전달되고, 이 함수는 앞의 25개까지의 항목으로 구성된 새로운 리스트를 반환한다.
println 함수는 입력 값을 출력하는데, 이 경우 입력은 앞의 25개의 정수에 대한 제곱 값으로 구성된 리스트다.
클로저(함수형 언어)와 자바의 차이
자바 프로그램은 가변 변수(mutable variable)를 사용하는데, 가변 변수는 프로그램 실행 중에 상태가 변할 수 있다.
앞의 예제에서 반복분을 제어하는 변수인 i가 가변 변수다.
클로저 프로그램에서는 이러한 가변 변수가 전혀 없다. 클로저에서는 x와 같은 변수가 한 번 초기화되면 절대로 변하지 않는다.
함수형 언어에서 변수는 변경되지 않는다.
불변성과 아키텍처
아키텍처를 고려할 때 이러한 내용이 왜 중요한가?
가변 변수로 인해 발생하는 문제들은 다음과 같다.
경합(race)
교착상태(deadlock)
동시 업데이트(concurrent update)
만약 어떠한 변수도 갱신되지 않는다면 경합 조건이나 동시 업데이트 문제가 일어나지 않는다.
락(lock)이 가변적이지 않다면 교착상태도 일어나지 않는다.
불변성이 가능하다면 이는 대체로 긍정적이다.
단, 저장 공간이 무한하고 프로세서의 속도가 무한히 빠르다고 전제하는 경우에 말이다.
자원은 무한대가 아니다. 따라서 일종의 타협이 필요하다.
가변성의 분리
불변성과 관련하여 가장 주요한 타협 중 하나는 애플리케이션, 또는 애플리케이션 내부의 서비스를 가변 컴포넌트와 불변 컴포넌트로 분리하는 일이다.
불변 컴포넌트에서는 순수하게 함수형 방식으로만 작업이 처리되며, 가변 변수는 사용되지 않는다.
불변 컴포넌트는 변수의 상태를 변경할 수 있는 순수 함수형 컴포넌트가 아닌 하나 이상의 다른 컴포넌트와 서로 통신한다.
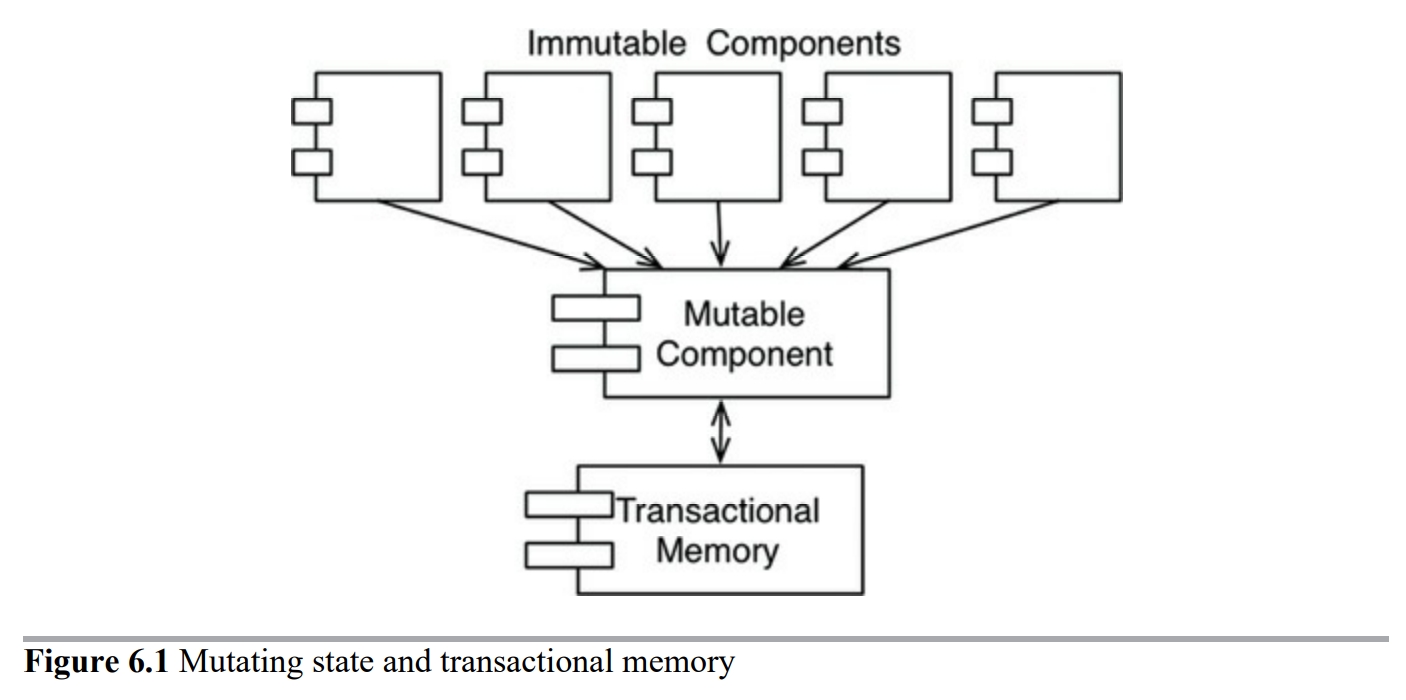
상태 변경은 컴포넌트를 여러 동시성 문제에 노출하는 꼴이므로, 흔히 트랜잭션 메모리와 같은 실천법을 사용하여 동시 업데이트와 경합 조건 문제로부터 가변 변수를 보호한다.
트랜젝션 메모리는 데이터베이스가 디스크의 레코드를 다루는 방식과 동일한 방식으로 메모리의 변수를 처리한다.
즉, 트랜잭션을 사용하거나 또는 재시도 기법을 통해 이들 변수를 보호한다.
이러한 접근법의 예시로 클로저의 atom 기능을 살펴보자.
(def counter (atom)) // counter를 0으로 초기화한다.
(swap! counter inc) // counter를 안전하게 증가시킨다.이 코드에서 counter 변수는 atom으로 정의되었다. atom은 특수한 형태의 변수로, 값을 변경하려면 반드시 swap! 함수를 사용해야 한다는 엄격한 제약이 걸려있따.
swap! 함수는 2개의 인자를 받는다.
하나는 변경할 atom 변수
다른 하나는 atom에 저장할 새로운 값을 계산할 함수다.
atom인 counter는 inc 함수가 계산한 값으로 변경되며, inc 함수는 단순히 인자 값을 1씩 증가시킨다.
swap! 함수는 전통적인 비교 및 스왑 알고리즘을 전략으로 사용한다.
counter의 값을 읽은 후 inc 함수로 전달한다.
inc 함수가 반환되면 counter의 값은 잠기게 된다.
inc 함수로 전달됐던 값과 비교한다.
만약 값이 같다면 inc 함수가 반환한 값이 counter에 저장된다.
만약 값이 같지 않다면 잠금을 해제한 후 이 전략을 처음부터 재시도한다.
atom 기능은 간단한 애플리케이션에는 적합하나 여러 변수가 상호 의존하는 상황에서는 동시 업데이트와 교착상태 문제로부터 완벽히 보호해주지 못한다.
따라서 애플리케이션을 제대로 구조화하려면 변수를 변경하는 컴포넌트와 변경하지 않는 컴포넌트를 분리해야 한다는 것이다.
현명한 아키텍트라면 가능한 한 많은 처리를 불변 컴포넌트로 옮겨야 하고, 가변 컴포넌트에서는 가능한 한 많은 코드를 빼내야 한다.
이벤트 소싱
저장 공간과 처리 능력의 한계는 급격히 사라지고 있다.
더 많은 메모리를 확보할수록, 기계가 더 빨라질수록 필요한 가변 상태는 더 적어진다.
간단한 예로, 고객 계좌를 관리하는 은행 어플리케이션을 생각해보자.
이 애플리케이션에서는 입금 트랜잭션과 출금 트랜잭션이 실행되면 잔고를 변경해야 한다.
여기서 계좌 잔고를 변경하는 대신 트랜잭션 자체를 저장한다고 생각해보자.
누군가 잔고 조회를 요청할 때마다 계좌 개설 시점부터 발생한 모든 트랜잭션을 단순히 더한다.
이 전략에서는 가변 변수가 하나도 필요 없다.
이는 시간이 지날수록 트랜잭션 수가 끝없이 증가하고, 잔고 계산에 필요한 컴퓨팅 자원은 걷잡을 수 없이 커진다.
-> 무한한 저장 공간과 무한한 처리 능력이 필요하다.
하지만 이 전략이 영원히 동작하게 만들 필요는 없다.
애플리케이션의 수명주기 동안에만 문제없이 동작할 정도의 저장 공간과 처리 능력만 있으면 충분할 것이다.
-> 이벤트 소싱에 깔려 있는 기본 발상이 바로 이것이다.
이벤트 소싱은 상태가 아닌 트랜잭션을 저장하자는 전략이다.
이벤트 소싱에서 상태가 필요해지면 단순히 상태의 시작점부터 모든 트랜잭션을 처리한다.
다음과 같이 지름길을 택할 수도 있다.
매일 자정에 상태를 계산한 후 저장한다.
이후 상태 정보가 필요해지면 자정 이후의 트랜잭션만을 처리하면 된다.
위 전략에 필요한 데이터 저장소는 어떠한가 실제로 오프라인 데이터 저장소는 급격히 증가하여 이제는 수테라바이트도 작다고 여기는 시대이다.
따라서 저장 공간을 충분히 확보할 수 있다.
더 중요한 점은 데이터 저장소에서 삭제되거나 변경되는 것이 하나도 없다는 사실이다.
결과적으로 애플리케이션은 CRUD가 아닌 CR만 수행한다.
데이터 저장소에서 변경과 삭제가 전혀 발생하지 않으므로 동시 업데이트 문제 또한 일어나지 않는다.
저장 공간과 처리 능력이 충분하면 애플리케이션이 완전한 불변성을 갖도록 만들 수도 있고 따라서 완전한 함수형으로 만들 수 있다.
위의 이야기는 터무니 없지 않다. 실제로 소스 코드 버전 관리 시스템이 정확히 위 방식으로 동작하고 있다(git, svn)
결론
프로그래밍 패러다임에 대해 요약하면 다음과 같다. \
구조적 프로그래밍은 제어흐름의 직접적인 전환에 부과되는 규율이다.
객체 지향 프로그래밍은 제어흐름의 간접적인 전환에 부과되는 규율이다.
함수형 프로그래밍은 변수 할당에 부과되는 규율이다.
세 패러다임 모두 우리에게서 무언가를 앗아갔다. 각 패러다임은 코드를 작성하는 방식의 형태를 한정시킨다.
지난 반세기 동안 배운 것은 해서는 안되는 것이다.
최초의 코드를 작성할 때 사용한 소프트웨어 규칙과 지금의 소프트웨어 규칙은 조금도 다르지 않다.
소프트웨어는 순차, 분기, 반복, 참조로 구성되며, 그 이상 그 이하도 아니다.
Last updated