
SRP: 단일 책임 원칙
SOLID 원칙 중에서 그 의미가 가장 잘 전달되지 못한 원칙은 바로 단일 책임 원칙이다.
-> 모든 모듈이 단 하나의 일만 해야 한다는 의미가 아니다.
단 하나의 일만 해야 한다는 원칙은 따로 있다.
바로 함수는 반드시 하나의, 단 하나의 일만 해야 한다는 원칙이다.
이 원칙은 커다란 함수를 작은 함수들로 리팩토링 하는 더 저수준에서 사용된다. 이 원칙은 SOLID 원칙이 아니며, SRP도 아니다.
SRP는 다음과 같이 기술되어 왔다.
단일 모듈은 변경의 이유가 하나, 오직 하나뿐이어야 한다.
소프트웨어 시스템은 사용자와 이해관계자를 만족시키기 위해 변경된다.
SRP가 말하는 '변경의 이유'란 바로 이들 사용자와 이해관계자를 가리킨다.
이 원칙은 아래와 같이 바꿔 말할 수도 있다.
하나의 모듈은 하나의, 오직 하나의 사용자 또는 이해관계자에 대해서만 책임져야 한다.
'사용자'와 '이해관계자'라는 단어는 사실 사용하기에 올바르지 않다. 사용자나 이해관계자가 두 명 이상일 수도 있기 때문이다.
여기에서는 집단, 즉 해당 변경을 요청하는 한 명 이상의 사람들을 가리킨다.
이를 액터(actor)라고 부르겠다.
하나의 모듈은 하나의, 오직 하나의 액터에 대해서만 책임져야 한다.
'모듈'이란 무엇인가? 가장 단순한 정의는 소스 파일이다.
하지만 일부 언어와 개발 환경에서는 코드를 소스 파일에 저장하지 않는다.
이러한 경우 모듈은 단순히 함수와 데이터 구조로 구성된 응집된 집합이다.
'응집된(cohesive)' 라는 단어가 SRP를 암시한다. 단일 액터를 책임지는 코드를 함께 묶어주는 힘이 바로 응집성(cohesion)이다.
이 원칙을 위반하는 다음 징후들을 살펴보자.
징후 1: 우발적 중복
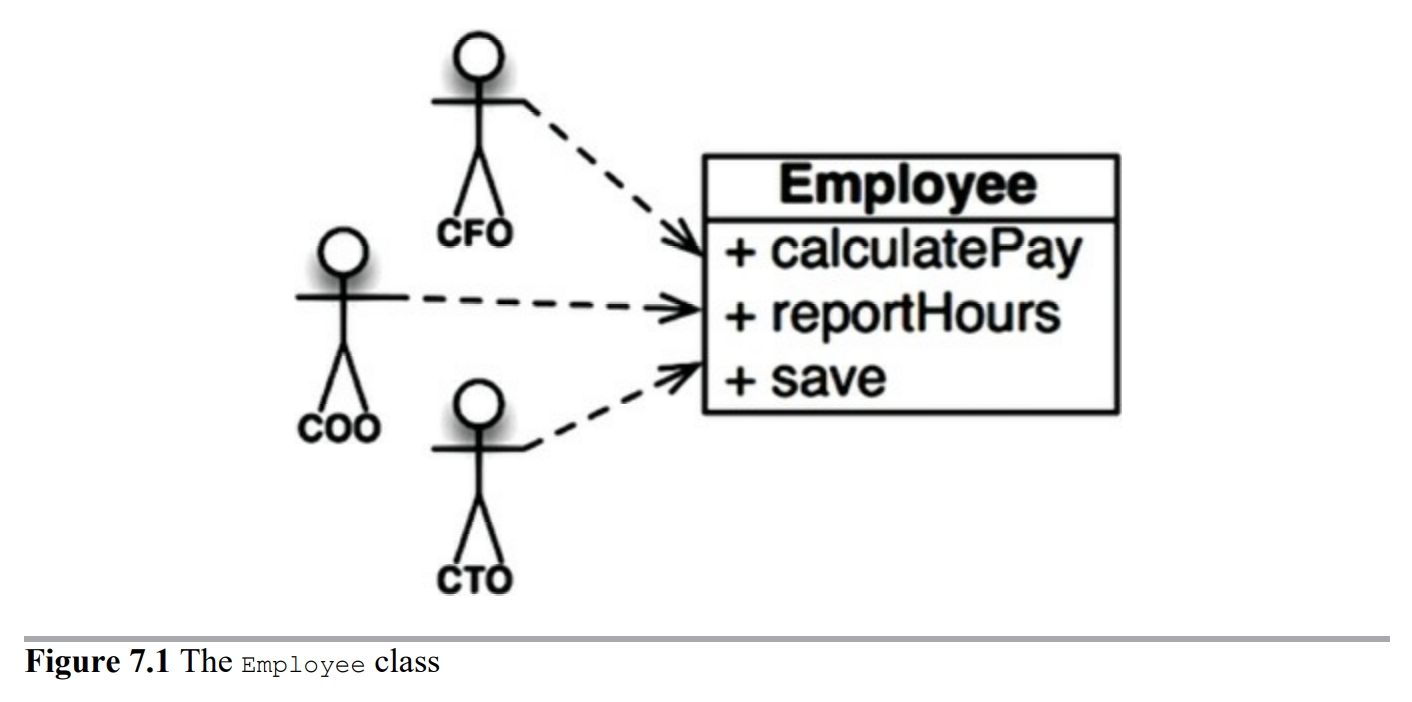
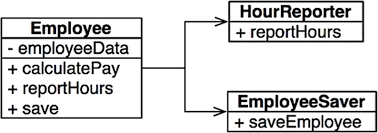
위 Employee 클래스는 세 가지 메서드 calulatePay(), reportHours(), save()를 가진다.
이 클래스는 SRP를 위반하는데, 이들 세 가지 메서드가 서로 매우 다른 세 명의 액터를 책임지기 때문이다.
calculatePay() 메서드는 회계팀에서 기능을 정의하며, CFO 보고를 위해 사용한다.
reportHours() 메서드는 인사팀에서 기능을 정의하고 사용하며, COO 보고를 위해 사용한다.
save() 메서드는 데이터베이스 관리자(DBA)가 기능을 정의하고, CTO 보고를 위해 사용한다.
개발자가 이 세 메서드를 Employee라는 단일 클래스에 배치하여 세 액터가 서로 결합되어 버렸다.
이로 인해 예를 들어 CFO 팀에서 결정한 조치가 COO팀이 의존하는 무언가에 영향을 줄 수 있다.
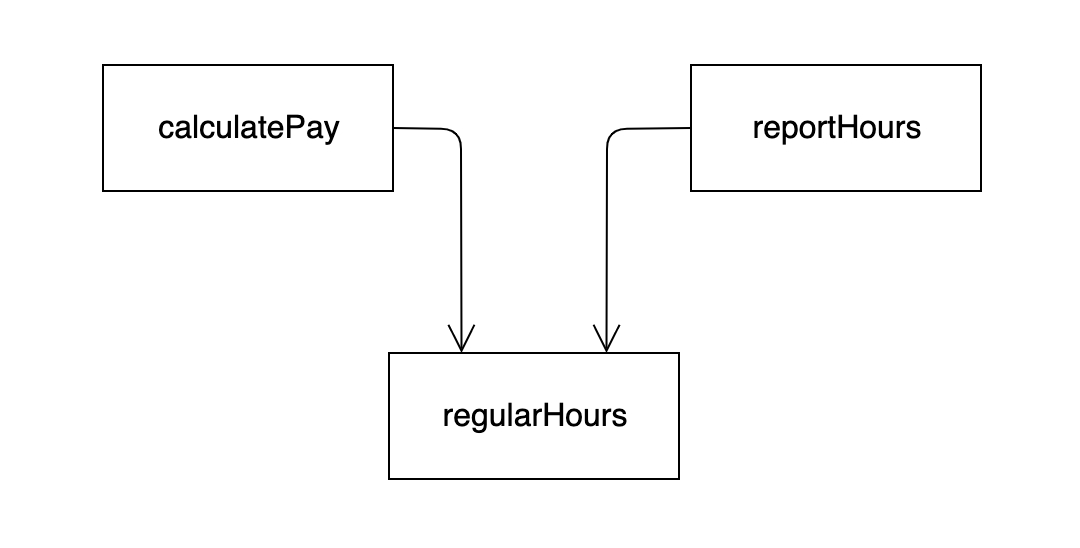
예를 들어, calculatePay() 메서드와 reportHours() 메서드가 초과 근무를 제외한 업무 시간을 계산하는 알고리즘을 공유한다고 해보자. 그리고 개발자는 코드 중복을 피하기 위해 이 알고리즘을 regularHours()라는 메서드에 넣었다고 해보자.
이제 CFO 팀에서 초과 근무를 제외한 업무 시간을 계산하는 방식을 약간 수정하기로 결정했다고 하자. 반면 인사를 담당하는 COO 팀에서는 초과 근무를 제외한 업무 시간을 CFO 팀과는 다른 목적으로 사용하기 때문에, 이 같은 변경을 원치 않는다고 해보자.
개발자는 calculatePay() 메서드가 regularHours()를 호출한다는 사실을 발견하지만 이 함수가 reportHours() 메서드에서도 호출도힌다는 사실은 눈치채지 못한다.
CFO 팀은 원하는 방식으로 동작하는지 검증하고 시스템을 배포한다.
하지만 COO 팀에서는 이러한 사실을 알지 못하고 결국 reportHours() 메서드가 COO팀에서 원하는 방식으로 동작하지 않아. 문제가 발생한다.
이러한 문제는 서로 다른 액터가 의존하는 코드를 너무 가까이 배치했기 때문에 발생한다.
SRP는 서로 다른 액터가 의존하는 코드를 서로 분리하라고 말한다.
징후 2: 병합
소스파일에 다양하고 많은 메서드를 포함하면 병합이 자주 발생할 수 있다.
특히 이들 메서드가 서로 다른 액터를 책임진다면 병합이 발생할 가능성은 높아진다.
예를 들어, DBA가 속한 CTO 팀에서 데이터베이스의 Employee 테이블 스키마를 수정하기로 결정했고, 동시에 인사 담당자가 속한 COO 팀에서는 reportHours() 메서드의 보고서 포맷을 변경하기로 결정했다고 해보자.
두 명의 서로 다른 개발자가 Employee 클래스를 체크아웃받은 후 변경사항을 적용한다.
이들 변경사항은 서로 충돌할 수 밖에 없다. 결과적으로 병합이 발생한 것이다.
이러한 문제를 벗어나는 방법은 서로 다른 액터를 뒷받침하는 코드를 서로 분리하는 것이다.
해결책
이러한 문제의 해결책은 다양하지만, 대부분이 메서드를 각기 다른 클래스로 이동 시키는 방식이다.
가장 확실한 해결책은 데이터와 메서드를 분리하는 방식일 것이다.
즉, 아무런 메서드가 없는 간단한 데이터 구조인 EmployeeData 클래스를 만들어, 세 개의 클래스가 공유하도록 한다.
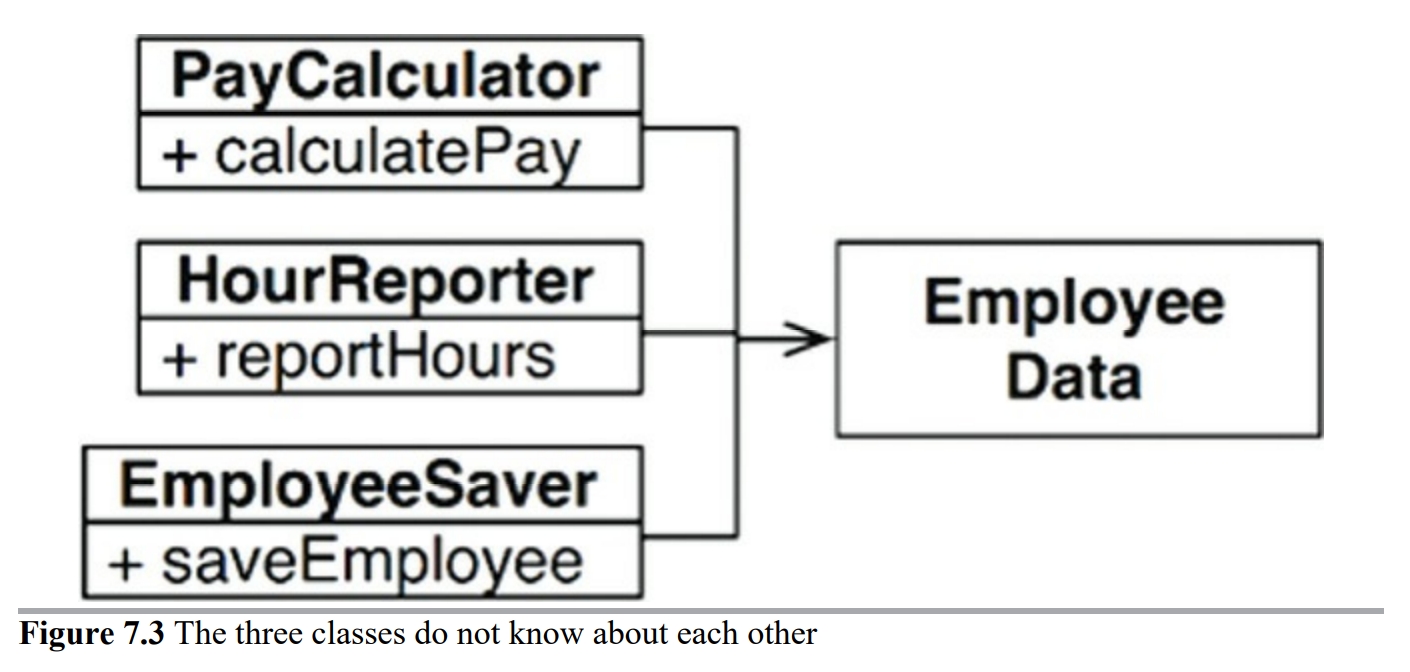
각 클래스는 자신의 메서드에 반드시 필요한 소스 코드만을 포함한다.
세 클래스는 서로의 존재를 몰라야 한다. 따라서 '우연한 중복'을 피할 수 있다.
반면에 위 해결책은 개발자가 세 가지 클래스를 인스턴스화하고 추적해야 한다는 게 단점이다.
이 단점을 해결하는 기법으로 퍼사드(Facade) 패턴이 있다.
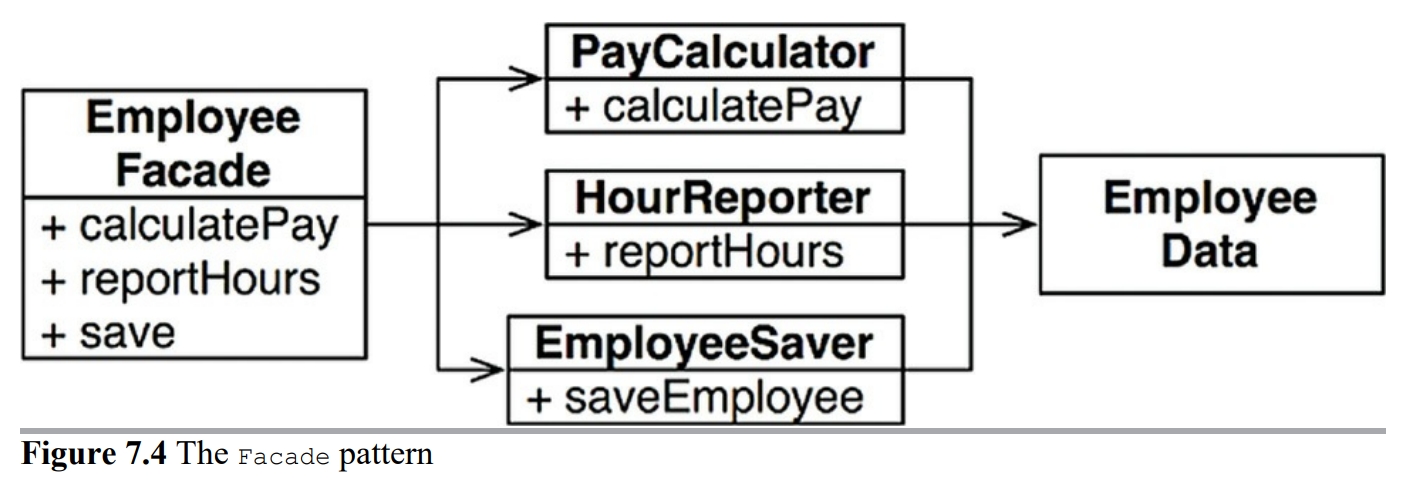
EmployeeFacade에 코드는 거의 없다. 이 클래스는 세 클래스의 객체를 생성하고, 요청된 메서드를 가지는 객체로 위임하는 일을 책임진다.
또 한, 어떤 개발자는 아래와 같이 가장 중요한 업무 규칙을 데이터와 가깝게 배치하는 방식을 선호한다.
모든 클래스는 반드시 단 하나의 메서드를 가져야 한다는 주장에 근거하면 앞의 해결책에 반대할 수도 있다.
하지만 실제로 각 클래스에서는 다수의 private 메서드를 포함할 것이다. (현실적으로)
여러 메서드가 하나의 가족을 이루고, 메서드의 가족을 포함하는 각 클래스는 하나의 유효범위가 된다.
해당 유효범위 바깥에서는 이 가족에게 감춰진 식구(private 멤버)가 있는지를 전혀 알 수 없다.
결론
단일 책임 원칙은 메서드와 클래스 수준의 원칙이다.
하지만 이보다 상위의 두 수준에서도 다른 형태로 다시 등장한다.
컴포넌트 수준에서는 공통 폐쇄 원칙이 된다.
아키텍처 수준에서는 아키텍처 경계의 생성을 책임지는 변경의 축이 된다.
Last updated