
ISP: 인터페이스 분리 원칙
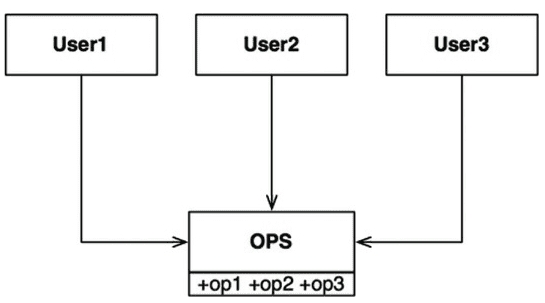
인터페이스 분리 원칙은 위 다이어그램에서 유래했다.
다수의 사용자가 OPS 클래스의 오퍼레이션을 사용한다.
User1은 오직 op1을 User2는 op2만을, User3는 op3만을 사용한다고 가정해보자.
그리고 OPS가 정적 타입 언어로 작성된 클래스라고 해보자. 이 경우 User1에서는 op2와 op3를 전혀 사용하지 않음에도 User1의 소스 코드는 이 두 메서드에 의존하게 된다.
이러한 의존성으로 인해 User1과 관련된 코드는 변경되지 않았어도 OPS 클래스에서 op2의 소스 코드가 변경되면 User1도 다시 컴파일 후 새로 배포해야 한다.
이러한 문제는 아래처럼 오퍼레이션을 인터페이스 단위로 분리하여 해결할 수 있다.
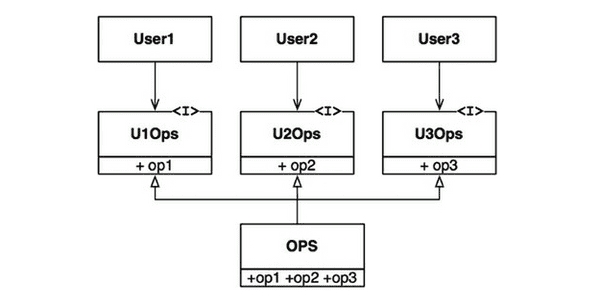
User1의 소스 코드는 U1Ops에 의존하지만 OPS에는 전혀 의존하지 않게 된다.
따라서 OPS에서 발생한 변경이 User1과는 전혀 관계없는 변경이라면, User1은 다시 컴파일하고 새로 배포하지 않아도 된다.
ISP와 언어
앞의 사례는 언어 타입에 의존한다. 정적 타입 언어는 사용자가 import, user 또는 include와 같은 타입 선언문을 사용하도록 강제한다. 이처럼 소스 코드에 포함된 include 선언문으로 인해 소스 코드 의존성이 발생하고, 이로 인해 재컴파일 또는 재배포가 강제된다.
루비나 파이썬과 같은 동적 타입 언어에서는 소스코드에 이러한 선언문이 존재하지 않는다.
대신 런타임에 추론이 발생한다. 따라서 소스코드 의존성이 아예 없으며, 재컴파일과 재배포가 필요없다.
동적 타입 언어를 사용하면 정적 타입 언어를 사용할 때보다 유연하며 결합도가 낮은 시스템을 만들 수 있는 이유는 바로 이 때문이다.
이러한 사실로 인해 ISP를 아키텍처가 아니라, 언어와 관련된 문제라고 결론내릴 여지가 있다.
*자바의 경우 정적 타입 언어지만, op2 메서드가 변경되면 이를 사용하는 User2만 재컴파일하면 된다. 이는 자바가 비-final, 비 private 인스턴스 변수에 대해서는 호출할 정확한 메서드를 런타임에 결정하는 늦은(late binding)을 수행하기 때문이다. 컴파일타임에는 호환되는 시그니처의 메서드가 타입 계층구조 어딘가에 존재하는지까지만 확인한다.
따라서 ISP는 언어종류에 따라 영향받는 정도가 다르다.
ISP와 아키텍처
ISP를 사용하는 근본적인 동기를 살펴보면, 잠재되어 있는 더 깊은 우려사항을 볼 수 있다.
일반적으로, 필요 이상으로 많은 걸 포함하는 모듈에 의존하는 것은 해로운 일이다. 소스 코드 의존성의 경우 이는 분명한 사실인데, 불필요한 재컴파일과 재배포를 강제하기 때문이다.
고수준인 아키텍처 수준에서도 마찬가지 상황이 발생한다.
예를 들어 S 시스템 구축에 참여하고 있는 아키텍트가 있다고 해보자.
아키텍트는 F라는 프레임워크를 시스템에 도입하기를 원한다. 그리고 F 프레임 워크 개발자는 특정한 D 데이터베이스를 반드시 사용하도록 만들었다고 가정해 보자. 따라서 S는 F에 의존하며, F는 D에 의존하게 된다.

F에서는 불필요한 기능, 따라서 S와는 전혀 관계없는 기능이 D에 포함된다고 가정하자.
그 기능 때문에 D 내부가 변경되면, F를 재배포해야 할 수도 있고, 따라서 S까지 재배포해야 할지 모른다.
더 심각한 문제는 D 내부의 기능 중 F와 S에서 불필요한 기능에 문제가 발생해도 F와 S에 영향을 준다는 사실이다.
결론
여기에서 배울 수 있는 교훈은 불필요한 짐을 실은 무언가에 의존하면 예상치도 못한 문제에 빠진다는 사실이다.
Last updated