
리액티브
리액터 프로젝트 필수 요소
목적 - 콜백 지옥, 깊게 중첩된 코드를 생략
가독성을 높이고 리액터 라이브러리에 의해 정의된 워크플로에 조합성(composability)를 추가
리액트 API 연산자로 실행 그래프를 제작
실제 구독을 만들기 전까지 아무 일도 발생하지 않으며 구독을 했을 때만 데이터 플로가 기동
비동기 요청의 결과를 효율적으로 처리가능
오류 처리 간단, 복원력 있는 코드 작성 가능
배압 제공
푸시 전용 : subscription.request(Long.MAX_VALUE)
풀 전용 : subscription.request(1)
풀-푸시 혼합
풀-푸시 모델 미 지원하는 이전 API 사용 시 예전 스타일의 배압 메커니즘 제공
리액터 추가
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-core</artifactId>
<version>3.2.0.RELEASE</version>
</dependency>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-test</artifactId>
<version>3.2.0.RELEASE</version>
<scope>test</scope>
</dependency>리액티브 타입 - Flux와 Mono
Flux
여러 요소를 생성할 수 있는 일반적인 리액티브 스트림을 정의
onNext x 0..N [onError | onComplete]
onNext x 0..N [onError | onComplete]Mono
최대 하나의 요소를 생성할 수 있는 스트림 정의
onNext x 0..1 [onError | onComplete]
onNext x 0..1 [onError | onComplete]Mono는 버퍼 중복과 값비싼 동기화 작업을 생략하여 Flux보다 효율적으로 사용 가능하다
CompletableFuture vs Mono
CompletableFuture : 즉시 처리를 시작
Mono: 구독자가 나타날 때까지 아무 작업도 수행하지 않는다.
사용법
Flux, Mono 시퀀스 만들기
리액티브 스트림 구독하기
subscribe()
사용자 정의 Subscriber 구현하기
subscriber 인터페이스 구현
연산자를 이용해 리액티브 시퀀스 변환하기
책에선 많은 연산자 예시를 다룬다.
매핑, 필터링, 수집, 원소 줄이기
스트림 조합 - concat, merge, zip, combineLatest
일괄처리 - buffer, windowing, grouping
flatMap, concatMap, flatMapSequential
샘플링 - sample
블로킹 구조로 변환 - toIterable, toStream, blockFirst, blockLast
시퀀스 처리동안 처리 내역 확인 - doOnNext, doOnComplete, doOnSubscribe, doOnTerminate
적합한 연산자는 아래의 링크 참고
Hot 스트림과 cold 스트림
콜드 퍼블리셔(cold publisher)
구독자가 나타날 때마다 해당 구독자에 대해 모든 시퀀스 데이터가 생성
구독자 없이는 데이터가 생성되지 않는다
구독자가 나타날 때마다 새로운 시퀀스가 생성 - HTTP 요청과 비슷한 동작
핫 퍼블리셔 (hot publisher)
데이터 생성은 구독자의 존재 여부에 의존하지 않는다
첫 번째 구독자가 구독을 시작하기 전에 원소를 만들어 내기 시작할 수 있다
구독자가 나타나면 이전에 생성된 값을 보내지 않고 새로운 값만 보낼 수 있다
이전의 기록은 보내지 않고 이후 업데이트만 보낸다
리액터 라이브러리에 포함된 대부분 핫 퍼블리셔는 processor 인터페이스를 상속한다
팩토리 메서드 just는 게시자가 빌드될 때 값이 한 번만 계산되고 새 구독자가 도착하면 다시 계산되지 않는 형태의 핫 퍼블리셔를 생성한다.
just는 defer로 래핑해 콜드 퍼블리셔로 전환할 수 있다.
스트림 원소를 여러 곳으로 보내기 - cold
Flux.publish - ConnectableFlux
스트림 내용 캐싱하기 - cold
Flux.cache
스트림 내용 공유 - hot
Flux.share
리액터 프로젝트 심화학습
리액티브 스트림의 수명주기
조립단계 (Assembly-time)
빌더패턴처럼 생겼지만 각각의 연산자가 새로운 객체를 생성함(*불변성 제공)
스트림 구성을 조작하고 더 나은 스트림 전달을 위한 다양한 기술을 적용할 수 있는 단계
조립 단계가 중요한 이유는, 단순히 객체들을 체이닝 시켜주는 것뿐만 아니라 필요한 경우에 조립 연산자를 바꿀 수 있기 때문이다.
이러한 형태의 최적화를 매크로 퓨전이라고 부른다
구독 단계 (Subscription-time)
조립단계에서 publisher에 일련의 체인으로 연결되어 있듯이 각 publisher에 대한 subscribe 메서드도 실행되기에 연결된 Subscriber 시퀀스가 존재하게 된다.
조립 단계와 동일한 최적화 수행가능
특정 Publisher를 구독할 때 발생
런타임 단계 (Runtime)
스트림 생명 주기의 마지막 단계
이 단계에서 publisher와 subscriber가 onSubscribe() 시그널과 request() 시그널을 교환하면서 스트림 실행이 시작된다 (게시자와 구독자가 교환하는 첫 두신호는 onSubscribe와 request이기 때문)
체인을 따라 request(n) 요청이 전파되고, 가장 안 쪽에 있는 ArraySubscription의 데이터 송신이 시작된다.
런타임 단계에서도 request() 호출 횟수를 줄이는 등의 최적화가 이루어진다. (마이크로 퓨전)
리액터에서 스레드 스케줄링 모델
리액터가 멀티스레딩 실행을 위해 제공하는 연산자와 연산자 사이의 차이점 확인
다른 워커로 실행을 전환할 수 있는 연산자 존재
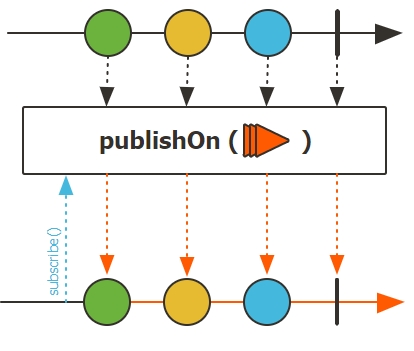
publishOn 연산자
런타임 실행 일부를 지정된 워커로 이동할 수 있게 해준다
publishOn 연산자는 내부적으로 전용 워커가 메시지를 하나씩 처리할 수 있도록 새로운 원소를 제공하는 큐를 가지고 있다.
리액티브 스트림의 모든 원소는 하나씩(동시에는 아니다) 처리되므로 항상 모든 이벤트에 순서를 엄격하게 정의할 수 있다. (이 속성을 직렬성(serializability)라 한다)
subscribeOn
구독 체인에서 워커의 작업 위치를 변경 가능
parallel
참고 : https://javacan.tistory.com/entry/Reactor-Start-7-Parallel
Flux.range(0, 10000)
.parallel()
.runOn(Schedulers.parallel())
.map()
.filter()
.subscribe()parallel() 연산자 하위 스트림에 대한 flow 분할과, 분할된 flow 간 균형 조정 역할을 한다.
parallel(parallelism) - 라운드 로빈 방식으로 데이터를 parallelism 개수의 rail로 나누어 제공한다.
Flux.parallel()은 ParallelFlux 객체를 반환하며, runOn(Scheduler) 를 통해 Flux가 생성하는 next 신호를 병렬로 처리할 수 있다.
Scheduler
Scheduler.schedule - Runnable 작업을 예약함
Scheduler.createWorker - 동일한 방법으로 Runnable 작업을 예약할 수 있는 Worker 인터페이스의 인스턴스 제공
Scheduler : Worker = 워커풀 : 스레드(리소스)
reactor는 세 가지 스케줄러 인터페이스 구현체를 제공한다.
SingleScheduler - 모든 작업을 한 개의 전용 워커에 예약한다. (Schduler.single())
ParallelScheduler - 고정된 크기의 작업자 풀에서 작동한다. (Schduler.parallel())
ElasticScheduler - 동적으로 작업자를 만들고 스레드 풀을 캐시한다 (Schduler.elastic())
리액터 컨텍스트(Context)
Context는 스트림을 따라 전달되는 인터페이스
런타임 단계에서 필요한 컨텍스트 정보에 액세스 할 수 있도록 한다.
비동기 리액티브 스트림에서 ThreadLocal이 가지는 한계를 극복
publishOn, subscribeOn을 통해 다른 워커에서 작업 플로를 수행하도록 하면 사용하는 스레드가 교체되어 이전에 쌓은 ThreadLocal 데이터에 접근하지 못함
프로젝트 리액터의 내부 구조
리액티브 스트림 수명 주기 및 연산자 융합
매크로 퓨전
조립 단계에서 발생
연산자를 다른 연산자로 교체
연산자로 인한 오버헤드를 줄이기 위해 사용된다.
업스트림 Publisher가 Callable 또는 ScalarCallable과 같은 인터페이스를 구현한 경우에 Publisher를 최적화된 연산자로 교체한다.
ex) 원소가 생성된 직후에 원소에 대한 실행을 다른 워커로 옮겨야 한다.
이때 queue에 원소를 입출력하기 위한 volatile 읽기 쓰기 발생
단순 Flux 타입 변환 작업이 지나치게 많이 실행
이때 publishOn 연산자를 추가 큐를 만들 필요가 없는 subscribeOn으로 치환
Flux.just(1)
.publishOn()
.map(...)마이크로 퓨전
Operator Fusion 추가 스터디
Macro-fusion
매크로 퓨전의 주요 타겟은 just(), empty(), fromCallable()이다.
이러한 단일 요소에 대하여 리액티브 스트림을 실행하는 것은 상당히 비싼 작업이다.
그렇기에 RxJava는 Single을, Reactor는 Mono를 도입하여 최적화를 제공한다.
Flux나 Observable이 0 또는 1개의 요소를 생성할 경우 Mono와 Single로 최적화를 할 수 있다.
또한 소스가 constant일 경우 커스텀한 연산자를 통해 소스를 인라인 할 수 있다.
0 또는 1개의 sychronous 소스를 생성할 때
Publisher가 java.util.concurrent.Callable을 구현할 때 0 또는 1개의 소스를 반환하는 것으로 간주한다
Callable<T>는 구독 시간에 수행되며 non-null한 T나, null 둘 중 하나를 반환한다.
null 일경우 empty로 간주하며, subscription.complete() 또는 subscription.error()를 호출한다.
non-null인 경우 onSubscribe로 반환 값을 넣은 subscription 전달
Callable을 상속하는 ScalarCallable도 위와 마찬가지
ScalarCallable은 Callable의 call을 오버라이드 하며 Exception 절을 제거했다.
컨슈머가 catch 하지 않아도 된다.
Micro-fusion
매크로 퓨전과 달리 둘 이상의 오퍼레이터가 리소스 또는 내부 구조를 공유할때 발생하며, 대부분 구독 타임에 일어난다.
micro-fusion의 첫 발상은 output 큐로 통하는 operator와 front 큐에서 시작하는 operator를 같은 queue를 사용하게 하는것이다. 이를 통해 메모리 할당, 동기화, drain loop를 줄일 수 있다. 이러한 발상이 소스에 존재하여 SpscArrayQueue 인스턴스의 생성을 완전히 피할 수 있게되었다.
SpscArrayQueue – single producer, single consumer, uses an array internally, bound capacity
아래의 operator에서 micro-fusion이 일어날 수 있다.
1) Conditional Subscriber
upstream이 **filter()**, **distinct()**로 필터링을 사용한다면, 한번의 filter 연산으로 생기는 element drop이 request(1)로 이어진다.
많은 requset(1) 호출은 atomic한 CAS 루프를 트리거하여 상대적으로 빠르게 오버헤드가 발생된다.
Conditional Subscriber는 실제로 값을 소비한 여부를 나타내는 boolean onNextIf(T v) 메서드를 제공한다. 이는 drain-loop가 CAS 카운터를 increment 하지않으며 요청한 request(limit)의 limit까지 원소를 받아올 수 있도록 한다.
onNextIf와 onNext의 차이점
onNextIf는 boolean값을 반환하기에 동기적인 실행이 강제된다. (onNext는 void)
하지만 boolean 값을 놓쳐도 onNext 실행처럼 간주한다면 추후 element가 부족할 경우 기존 방식은 request(1)을 통해 재요청이 가능하다
2) Synchronous-fusion
when the source to an operator is synchronous in nature, and can pretend to be a Queue itself.
연산자의 소스가 본질적으로 동기식이고 큐 그 자체인 것처럼 가장할 수 있는 경우
동기적 마이크로 퓨전이라고 부른다.
다음과 같은 연산자가 위의 조건을 만족하는 연산자이다.
**range(), fromIterable(), fromArray(), fromStream(), fromCallable()**.
아이디어는 소스의 Subscription이 Queue를 구현하도록 하는것이다. 구독 타임에 onSubscribe()가 이를 큐를 직접 체크하는것. (새로운 큐를 만들지 않고)
이는 upstream의 operator와 자기 자신(operator) 모두의 mode switch가 필요하다. 이때 mode switching이란 request() 메서드를 호출하지 않고queue.poll()을 통해 element를 받아오는 방식을 의미한다.
3) Asynchronous-fusion
내부의 큐를 가진 소스, 그 큐에 요청하여 값을 가져오는 다운스트림, 업스트림에서 내려주는 항목의 타이밍과 개수를 알 수 없는 상황.
Source에서 Queue 인터페이스를 구현하는 방법을 사용해도 되지만, 프로토콜 체인지는 필요하게 된다.
그렇기에 Subscription이 Queue를 구현하는 것 대신, Subscription과 Queue를 구현하는 QueueSubscription 인터페이스를 제공한다. requestFusion()으로 가져올 수 있다.
requestFusion() 메서드는 int형 플래그를 통해 업스트림에 현재의 operator가 어떤 형태의 퓨전을 원하고 지원하는지 전달하며, 업스트림은 전달받은 형태의 퓨전 모드를 활성화하는 식으로 응답한다.
Last updated