
관례
코틀린에서 관례(convention)를 사용하는 하나의 예는 산술 연산자다. 자바에서는 원시 타입에 대해서만 산술 연산자를 사용할 수 있고, 추가로 String에 대해 + 연산자를 사용할 수 있다. 이러한 기술들을 convention이라고 하는데, 이 장에서는 다양한 convention과 그들을 사용하는 예를 보려고 한다. convention을 사용함으로써 이미 존재하는 자바 클래스를 수정하지 않고도 확장하는 것이 가능하다.
산술 연산자 오버로딩
이항 산술 연산 오버로딩
data class Point(val x: Int, val y: Int) {
operator fun plus(other: Point): Point {
return Point(x + other.x, y + other.y)
}
}
>>> val p1 = Point(10, 20)
>>> val p2 = Point(30, 40)
>>> println(p1 + p2)
Point(x=40, y=60)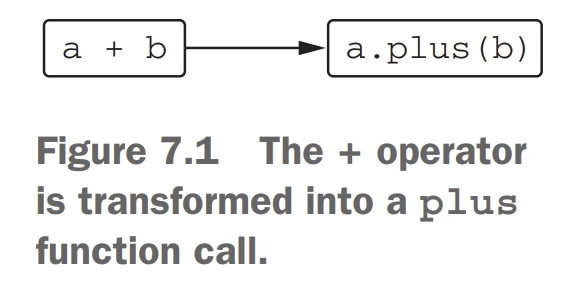
operator 키워드를 plus 함수를 선언할 때 써 주면, + 기호로 두 Point 객체를 더할 수 있다. 이는 해당 함수를 해당 규칙의 구현으로 사용할 의도가 있으며 실수로 일치하는 이름을 가진 함수를 정의하지 않았음을 명시한다.
📌 참고: 오버로딩 가능한 이항 산술 연산자 표
a * b
times
a / b
div
a % b
mod
a + b
plus
a - b
minus
코틀린에서는 operator를 오버로딩하는 것이 비교적 간단한데, 그 이유는 자신만의 operator를 선언하는 것이 불가능하며 코틀린에서 제한하고 있는 set로만 가능하기 때문이다. 또한 각 Expression은 그와 짝이 맞는 Function name이 존재한다. 해당 짝 목록은 옆에 표와 같다. 이러한 연산자의 연산 순서는 산술 연산자와 같다. 예를 들어, a + b * c 은 항상 *먼저 계산되며, + 는 나중에 계산된다.
다른 타입을 가지는 연산자
operator fun Char.times(count: Int): String {
return toString().repeat(count)
}
>>> println('a' * 3)
aaa위의 식에서는 Char와 Int를 각각 연산항으로 가진다. 그 결과는 String이다. 코틀틀린에서는 이런 식의 조합 또한 완벽하게 수용 가능하다.
💡 참고: 비트 연산자 코틀린에서는 비트 연산자에 대해 자신만의 타입을 설정할 수 있도록 지원하지 않는다. 이러한 연산에 대해서는 중위 표기법(infix call syntax)으로 표현하는 일반 함수만 지원된다.
>>> println(0x0F and 0xF0)
0
>>> println(0x0F or 0xF0)
255
>>> println(0x1 shl 4)
16복합 대입 연산자 오버로딩
plus라고 operator를 정의내릴 때, 코틀린은 + 뿐만 아니라 +=까지 지원한다. 코틀린 표준 라이브러리는 변경 가능한 컬렉션에 대해 plusAssign을 정의할 수 있다. 다른 산술 연산자도 minusAssign, timesAssign, …등으로 연산 가능하다.
>>> var point = Point(1, 2)
>>> point += Point(3, 4)
>>> println(point)
Point(x=4, y=6)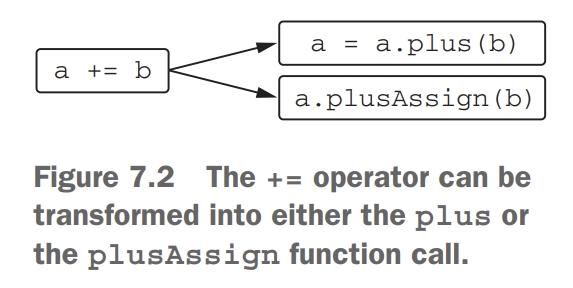
이론적으로, 코드에서 +=를 사용할 때, plus와 plusAssign 함수가 모두 호출될 수 있다. 이런 경우에 두 함수가 모두 정의되어 있고 실행 가능한 상황이라면, 컴파일러는 오류를 호출할 것이다. 이럴 경우 해결할 수 있는 방법은 operator를 regular function call로 바꾸는 것이다. 또 다른 방법은 var을 val로 바꾸어 plusAssign을 실행 불가능하게 만드는 것이다.
하지만 일반적으로는 새로운 클래스를 만드는 것이 좋다. 즉, 오직 plusAssign와 비슷한 다른 연산을 지원하는 변경 가능한 클래스를 만들면 된다.
여태까지는 이항 연산자 오버로딩에 대해 이야기했다. 이제 단항 연산자 오버로딩을 이야기해보자.
단항 연산자 오버로딩
operator fun Point.unaryMinus(): Point {
return Point(-x, -y)
}
>>> val p = Point(10, 20)
>>> println(-p)
Point(x=-10, y=-20)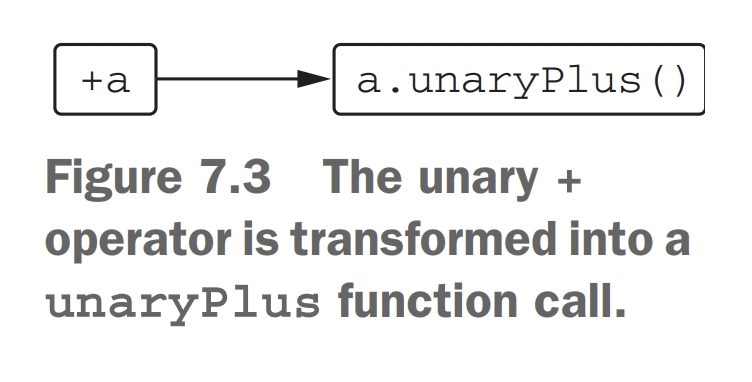
단항 연산자의 경우 함수는 그 어떠한 인수도 받지 않는다. 단항 연산자는 이항 연산자와 같은 방식으로 작동한다. 사용할 수 있는 연산자 목록은 아래 표와 같다.
📌오버로딩할 수 있는 단항 산술 연산자 표
+a
unaryPlus
-a
unaryMinus
!a
not
++a, a++
inc
--a, a--
dec
inc와 dec는 접두에 붙느냐 접미에 붙느냐에 따라서 반환하는 값이 달라진다. 접두에 붙으면 연산을 진행하기 전의 값이 반환되고, 접미에 붙으면 연산을 진행한 후의 값이 반환된다.
>>> println(bd++)
0
>>> println(++bd)
2비교 연산자 오버로딩
코틀린에서는 Primitive 타입 뿐만 아니라 모든 객체에 대한 비교 연산(==, !=, >, <)을 수행할 수 있다. eqauls나 compareTo를 호출해야하는 자바와 달리 코틀린에서는 == 비교 연산자를 직접 사용할 수 있어 훨씬 직관적이다.
동등성 연산자 : eqauls
코틀린에서 a == b를 사용하게 되면, a?.equals(b) ?: (b == null)로 번역된다. != 또한 자동으로 equals로 자동 번역된다. 위에서 언급한 Point 클래스의 경우 data class(코틀린의 data class는 생성자부터 getter & setter를 자동으로 만들어줌)로 표시했기 때문에 컴파일러에 의해 동등한 구현이 자동으로 생성됩니다. 하지만 수동으로 구현했다면, 코드는 다음과 같다.
class Point(val x: Int, val y: Int) {
override fun equals(obj: Any?): Boolean {
if (obj === this) return true
if (obj !is Point) return false
return obj.x == x && obj.y == y
}
}
>>> println(Point(10, 20) == Point(10, 20))
true
>>> println(Point(10, 20) != Point(5, 5))
true
>>> println(null == Point(1, 2))
false이때 식별자 비교 연산자 ===를 사용해 파라미터, 즉 두 객체 간의 참조가 같은지를 비교할 수 있다. 이는 자바의 ==와 정확하게 같은 역할을 한다. 단, ===는 오버로딩할 수 없다.
순서 연산자 : compareTo
코틀린에서는 a >= b를 작성하면 a.compareTo(b) >= 0가 호출된다(자바에서는 이렇게 줄일 수 있는 방법이 없다). 이때 compareTo가 반환하는 값은 Int이다.
class Person(
val firstName: String, val lastName: String
) : Comparable<Person> {
override fun compareTo(other: Person): Int {
return compareValuesBy(this, other,
Person::lastName, Person::firstName)
}
}위 코드는 코틀린 표준 라이브러리의 compareValuesBy 함수를 사용 compareTo를 쉽고 간결하게 정의할 수 있다.
컬렉션과 범위에 대해 쓸 수 있는 관례
컬렉션을 다룰 때 가장 많이 쓰이는 연산은 a[b]와 같이 인덱스를 사용해 원소를 읽거나 쓰는 연산과 in을 사용하여 어떤 값이 컬렉션에 속해있는지 검사하는 연산이다. 이런 식으로 컬렉션과 범위에 대해 사용하는 Conventions를 살펴보자.
인덱스로 원소에 접근 : get과 set
코틀린에서 인덱스 연산자는 Convention에 가깝다. 인덱스 연산자는 get 연산자 메소드로 번역되고, 원소를 쓰는 연산은 set연산자 메소드로 변환된다. 이때 이를 구현하고 사용하는 방법은 다음과 같다.
operator fun Point.get(index: Int): Int {
return when(index) {
0 -> x
1 -> y
else ->
throw IndexOutOfBoundsException("Invalid coordinate $index")
}
}
>>> val p = Point(10, 20)
>>> println(p[1])
20이때 해야 할 일은 get이라는 함수를 만든 후, 이를 operator로 명시하는 것이다. 이렇게 하고 난 후에는 x[a, b]를 호출하면 x.get(a, b)로 변환된다. get의 파라미터는 단지 Int 뿐만 아니라 다양한 것이 될 수 있다. set의 경우에는 x[a, b] = c로 작성하면, 자동으로 x.set(a, b, c)로 변환된다.
또한 만약 2차원 행렬을 표현하는 클래스에는 operator fun get(rowIndex:Int, colIndex:int)를 정의하면 matrix[row,col]로 해당 메소드를 호출하는 것이 가능하다.
in 관례
컬렉션에 의해 제공되는 다른 연산자는 in 연산자이다. 이는 특정 객체가 컬랙션에 속하는지 검사하는 역할을 한다. 이와 매칭되는 함수는 contains이다. 즉, a in c가 c.contains(a)로 변환된다.
data class Rectangle(val upperLeft: Point, val lowerRight: Point)
operator fun Rectangle.contains(p: Point): Boolean {
return p.x in upperLeft.x until lowerRight.x &&
p.y in upperLeft.y until lowerRight.y
}
>>> val rect = Rectangle(Point(10, 20), Point(50, 50))
>>> println(Point(20, 30) in rect)
true
>>> println(Point(5, 5) in rect)
false위의 코드에서는 until 스텐다드 라이브러리를 확인할 수 있다. 이는 개방된 범위(open range)를 만들기 위해서 사용된다. 개방 범위는 ending point가 존재하지 않는 범위이다. 보통 닫힌 범위의 경우, 10..20은 10에서부터 20까지를 의미한다. 그러나 10 until 20의 경우에는 10에서부터 19까지만 포함한다.
rangeTo 관례
범위를 만들기 위해서는, ..를 사용해야 한다. 1..10은 1에서부터 10까지를 의미한다. 이때 start..end는 start.rangeTo(end)로 변환된다. rangeTo 함수는 직접 클래스를 만들어야 한다. 그러나 Comparable 인터페이스를 구현하는 경우에는 클래스 생성이 필요 없다. 이 경우에는 비교 가능한 모든 원소에 대해 범위를 생성할 수 있다.
operator fun <T: Comparable<T>> T.rangeTo(that: T): ClosedRange<T>이 함수는 서로 다른 원소들 간의 비교를 가능하게 한다.
for 루프를 위한 iterator 관례
코틀린에서 for 루프는 범위 검사와 마찬가지로 in 연산자를 사용하지만, 그 의미는 약간 다르다. for(x in list) { ... }의 경우 list.iterator()를 호출해서 iterator를 얻은 다음, 자바와 마찬가지로 iterator에 대해 hasNext와 next 호출을 반복하는 식으로 변환된다. 코틀린에서는 이 또한 convention으로 iterator 메소드를 확장 함수로 정의할 수 있다.
operator fun CharSequence.iterator(): CharIterator
>>> for (c in "abc") {} //이 라이브러리는 함수가 string에 대해 반복할 수 있게 만듬구조 분해(destructuring declarations) 선언과 component 함수
구조 분해를 사용하며 복합적인 값을 분해해서 여러 변수를 한꺼번에 초기화할 수 있다.
>>> val p = Point(10, 20)
>>> val (x, y) = p
>>> println(x)
10
>>> println(y)
20즉, val (a, b) = p는 val a = p.component1()와 val b = p.component2()가 된다. data 클래스의 주 생성자에 들어있는 프로퍼티에 대해서는 컴파일러가 자동으로 componentN함수를 만들어준다.
class Point(val x: Int, val y: Int) {
operator fun component1() = x
operator fun component2() = y
}이렇게 구조 분해를 사용하는 이유는 여러 개의 변수를 리턴하는데 사용할 수 있기 때문이다. 또한 split를 사용하여 두 개의 원소 리스트를 리턴할 수도 있다.
data class NameComponents(
val name: String,
val extension: String)
fun splitFilename(fullName: String): NameComponents {
val (name, extension) = fullName.split('.', limit = 2)
return NameComponents(name, extension)
}구조 분해 선언과 루프
구조 분해 선언은 변수를 선언할 때도 사용할 수 있다. 예를 들어, 루프에서도 사용 가능하다.
fun printEntries(map: Map<String, String>) {
for ((key, value) in map) {
println("$key -> $value")
}
}
>>> val map = mapOf("Oracle" to "Java", "JetBrains" to "Kotlin")
>>> printEntries(map)
Oracle -> Java
JetBrains -> Kotlin위의 예시는 두 가지 관례를 사용하는데, 하나는 객체를 iterate하는 것이고 다른 하나는 구조 분해 선언을 하는 것이다. 코틀린의 라이브러리에서는 map에 대한 확장 함수로 iterator가 들어있고, 이는 map에 대한 iterator를 제공한다. 따라서, 자바와 다르게 map을 직접 iterate할 수 있다.
프로퍼티 접근자 로직 재활용 : 위임 프로퍼티
위임 프로퍼티 (delegated property)는 코틀린이 제공하는 관례에 의존하는 특성 중 가장 강력한 기능을 갖고 있다. 위임 프로퍼티를 사용하면 값을 backing field에 단순히 저장하는 것보다 더 복잡한 방식으로 작동하는 프로퍼티를 쉽게 구현할 수 있다. 예를 들어 프로퍼티는 delegate을 사용해 자신의 값을 필드가 아니라 데이터베이스 테이블이나 브라우저 세션, 맵 등에 저장할 수 있다.
위임 프로퍼티 기본
위임 프로퍼티의 일반적인 문법은 다음과 같다.
class Foo {
var p: Type by Delegate()
}프로퍼티 p는 다른 객체에게 자신의 로직을 위임한다. 이 예시에서는 Delegate 클래스가 된다. 이는 by 키워드를 통해 뒤에 있는 식을 계산해서 위임에 쓰일 객체를 얻을 수 있다.
class Delegate {
operator fun getValue(...) { ... } //getter에 대한 로직을 가지고 있음
operator fun setValue(..., value: Type) { ... } //setter에 대한 로직을 가지고 있음
}
class Foo {
var p: Type by Delegate() //by 키워드는 프로퍼티를 위임 객체와 관계맺음
}
>>> val foo = Foo()
>>> val oldValue = foo.p //foo.p는 delegate.getValue(…)를 호출함
>>> foo.p = newValue //프로퍼티 값을 delegate.setValue(…, newValue)를 호출해 바꿈foo.p처럼 접근하였지만, 이는 사실 도우미 프로퍼티인 Delegate 타입이 호출된 것이다.
위임 프로퍼티 사용 : by lazy()를 사용한 프로퍼티 초기화 지연
lazy initialization은 객체의 일부분을 초기화하지 않고 남겨뒀다가 실제 그 부분의 값이 필요한 경우 초기화 할 때 흔히 쓰이는 패턴이다. 예를 들어 person 클래스가 자신이 작성한 이메일의 목록을 제공한다고 할 때, 이메일은 데이터베이스에 들어있고 불러오려면 시간이 오래 걸린다. 따라서 이메일 프로퍼티의 값을 최초로 사용할 때 단 한 번만 이메일을 데이터베이스에서 가져오는 것이 효율적이다. 데이터베이스에서 이메일을 가져오는 loadEmails라는 함수가 있다고 할 때, 이메일을 불러오기 전에는 null을 저장하고 불러온 다음에는 이메일 리스트를 저장하는 _emails 프로퍼티를 추가해서 지연 초기화를 구현할 수 있다.
class Person(val name: String) {
private var _emails: List<Email>? = null
val emails: List<Email>
get() {
if (_emails == null) {
_emails = loadEmails(this)
}
return _emails!!
}
}
>>> val p = Person("Alice")
>>> p.emails
Load emails for Alice
>>> p.emails하지만 위의 코드는 굉장히 번거롭고 복잡하다. 이때, 위임 프로퍼티를 사용하면 코드가 더 간편해진다.
class person(val name:String){
val emails by lazy {loadEmails(this) }
}lazy 함수는 getValue 메소드가 들어있는 객체를 반환한다. 또한, lazy 함수는 기본적으로 스레드 안전하다. 즉, lazy를 by와 함께 사용함으로써 간편하게 위임 프로퍼티를 만들 수 있다.
위임 프로퍼티 구현
위임 프로퍼티가 구현되는 방식을 보기 위해서 다른 예제를 살펴보자. 객체가 UI상에서 표현되고 이를 자동으로 업데이트하고 싶다면, 자바에서는 PropertyChangeSupport나 PropertyChangeEvent를 사용하면 된다. 이를 코틀린에서 위임 프로퍼티 없이 사용하는 법과, 위임 프로퍼티를 사용해 리펙토링하는 법을 배워보자.
class Person(
val name: String, age: Int, salary: Int
) : PropertyChangeAware() {
var age: Int = age
set(newValue) {
val oldValue = field
field = newValue
changeSupport.firePropertyChange(
"age", oldValue, newValue)
}
var salary: Int = salary
set(newValue) {
val oldValue = field
field = newValue
changeSupport.firePropertyChange(
"salary", oldValue, newValue)
}
}이는 상당히 많은 setter 코드를 반복하고 있다. 이를 helper class를 사용하여 바꾸어 보자.
class ObservableProperty(
val propName: String, var propValue: Int,
val changeSupport: PropertyChangeSupport
) {
fun getValue(): Int = propValue
fun setValue(newValue: Int) {
val oldValue = propValue
propValue = newValue
changeSupport.firePropertyChange(propName, oldValue, newValue)
}
}
class Person(
val name: String, age: Int, salary: Int
) : PropertyChangeAware() {
val _age = ObservableProperty("age", age, changeSupport)
var age: Int
get() = _age.getValue()
set(value) { _age.setValue(value) }
val _salary = ObservableProperty("salary", salary, changeSupport)
var salary: Int
get() = _salary.getValue()
set(value) { _salary.setValue(value) }
}위의 코드는 프로퍼티를 저장하는 코드를 생성하여 해당 프로퍼티가 수정될 때마다 자동으로 이를 반영한다. 반복되는 로직을 없앴지만, 여전히 ObservableProperty를 생성하기 위해서는 보일러플레이트 코드가 사용된다. 이를 방지하기 위해서 위임 프로퍼티를 사용할 수 있다. 우선 이를 사용하기 위해 ObservableProperty를 다음과 같이 바꾼다.
class ObservableProperty(
var propValue: Int, val changeSupport: PropertyChangeSupport
) {
operator fun getValue(p: Person, prop: KProperty<*>): Int = propValue
operator fun setValue(p: Person, prop: KProperty<*>, newValue: Int) {
val oldValue = propValue
propValue = newValue
changeSupport.firePropertyChange(prop.name, oldValue, newValue)
}
}그 후 Person class를 다음과 같이 변경한다.
class Person(
val name: String, age: Int, salary: Int
) : PropertyChangeAware() {
var age: Int by ObservableProperty(age, changeSupport)
var salary: Int by ObservableProperty(salary, changeSupport)
}by 키워드를 통해, 코틀린 컴파일러는 자동으로 변경사항을 반영한다. 이때 by 키워드의 오른쪽에 있는 것이 delegate(위임)이다.
위임 프로퍼티 컴파일 규칙
위임 프로퍼티 컴파일 규칙을 정리해보자. 다음과 같은 위임 프로퍼티가 있다고 가정하자.
class C {
var prop: Type by MyDelegate()
}
val c = C()위의 코드를 컴파일하면 컴파일러는 다음과 같은 코드를 생성한다.
class C {
private val <delegate> = MyDelegate() //hidden property
var prop: Typeget() = <delegate>.getValue(this, <property>)
set(value: Type) = <delegate>.setValue(this, <property>, value)
}
즉, 다시 말해 컴파일러는 모든 프로퍼티 접근자 안에 getValue와 setValue 호출 코드를 생성해준다고 할 수 있다.
프로퍼티 값을 맵에 저장
위임 프로퍼티를 사용할 때 또 흔하게 사용되는 패턴은 동적으로 정의되는 특성을 가진 객체를 정의하는 것이다. 이런 객체를 확장 가능한 객체(expando objects)라고 부른다.
class Person {
private val _attributes = hashMapOf<String,String>()
fun setAttribute(attrName: String, value: String){
_attributes[attrName] = value
}
val name: String by _attributes // 위임 프로퍼티로 맵을 사용
}위의 코드가 작동하는 이유는 표준 라이브러리가 Map과 MutableMap 인터페이스에 대해 getValue와 setValue 확장 함수를 제공하기 때문이다.
프레임워크에서 위임 프로퍼티 활용
객체 프로퍼티를 저장하거나 변경하는 방법을 바꿀 수 있으면 프레임워크를 개발할 때 유용하게 사용할 수 있다.
objectUsers:IdTable() {
val name =varchar("name",length=50).index()
val age =integer("age")
}
classUser(id:EntityID) :Entity(id) {
var name:StringbyUsers.name
var age:IntbyUsers.age
}Last updated