
고차함수
고차 함수 정의
고차 함수는 다음과 같다:
다른 함수를 인자로 받거나 리턴하는 함수
예를 들어, 아래의 filter 함수는 서술부에 함수를 가지고 있기 때문에 이를 고차 함수라고 할 수 있다.
list.filter{ x > 0 }함수 타입
람다 인자의 타입은 아래와 같이 선언한다.
(파라미터 타입, ...) -> 반환 타입
예를 들어, sum 함수는 Int 타입인 파라미터 2개(x, y)를 받아서 Int 값을 반환하는 함수이며 action은 함수를 반환하는 함수이다.
val sum = { x: Int, y: Int -> x + y }
val action = { println(42) }이를 좀 더 명시적으로 표현하자면, 즉 위에서 말한 선언 방법대로 선언하자면 다음과 같다. 이때 코드의 가독성을 위해 (x: Int, y: Int) ‐> Int식으로 변수의 이름을 명시할 수 있다. Unit 타입은 함수 반환 타입에만 쓰는 특별한 타입이다.
val sum: (Int, Int) -> Int = { x, y -> x + y }
val action: () -> Unit = { println(42) } //함수를 반환한다다른 함수와 마찬가지로, 리턴 타입으로 nullable을 사용할 수 있다.
var canReturnNull: (Int, Int) -> Int? = { null }
var funOrNull: ((Int, Int) -> Int)? = null //함수의 반환타입이 아닌, var 자체가 nullable 인자로 받은 함수 호출
인자로 받은 함수를 호출하는 방식은 일반적인 함수를 호출하는 방식과 같다. 함수 이름 뒤에 () 괄호를 넣어주고, 괄호 안에 파라미터를 넣어주면 된다.
fun twoAndThree(operation: (Int, Int) ‐> Int) { ////function 타입의 파라미터 선언
val result = operation(2, 3) //function 타입의 파라미터 호출
println("The result is $result")
}
>>> twoAndThree { a, b -> a + b }
The result is 5
>>> twoAndThree { a, b -> a * b }
The result is 6다음과 같은 함수를 보면, 문자가 알파벳일 경우에만 골라서 리턴해주는 함수이다.
💡 참고: 코틀린에서 함수 선언
fun [리시버 타입.]함수 이름([매개변수 이름: 자료형, ..]): [반환값의 자료형] {
표현식...
[return 반환값]
}fun String.filter(predicate: (Char) -> Boolean): String { //함수를 파라미터로 가짐
val sb = StringBuilder()
for (index in 0 until length) {
val element = get(index)
if (predicate(element)) sb.append(element)
}
return sb.toString()
}
>>> println("ab1c".filter { it in 'a'..'z' })
abc자바에서 코틀린 함수 타입 사용
자바에서 코틀린 함수 타입은 인터페이스로 바뀐다. 함수 타입의 변수는 FunctionN 인터페이스를 구현하는 객체를 저장한다. 코틀린 표준 라이브러리는 함수 인자의 개수에 따라 Function0<R> (인자가 없는 함수), Function1<P1, R> (인자가 하나인 함수) 등의 인터페이스를 제공한다. 각 인터페이스에는 invoke 메소드가 있는데, 이를 호출하면 함수를 실행할 수 있다. 함수 타입인 변수는 인자 개수에 따라 적당한 FunctionN 인터페이스를 구현하는 클래스의 인스턴스를 저장하고 있으며, 그 클래스의 invoke 메소드 본문에는 람다의 본문이 들어간다.
/* Kotlin declaration */
fun processTheAnswer(f: (Int) -> Int) {
println(f(42))
}
/* Java */
>>> processTheAnswer(
new Function1<Integer, Integer>() {
@Override
public Integer invoke(Integer number) {
System.out.println(number);
return number + 1;
}
});
43디폴트 값 또는 널이 될 수 있는 함수 타입 파라미터
함수 타입으로 파라미터를 선언할 때, 디폴트 값 또한 명시할 수 있다.
fun <T> Collection<T>.joinToString(
separator: String = ", ",
prefix: String = "",
postfix: String = "",
transform: (T) -> String = { it.toString() }
): String {
val result = StringBuilder(prefix)
for ((index, element) in this.withIndex()) {
if (index > 0) result.append(separator)
result.append(transform(element))
}
result.append(postfix)
return result.toString()
}위의 코드에서는 디폴트로 toString() 변환이 일어나기 때문에 result.append(transform(element))에서 element를 항상 String으로 유지할 수 있다. 따라서 append()를 사용하는 것이 가능하다. 이 코드에서 nullable한 파라미터를 함수 타입으로 고치고 싶다면 다음과 같이 해주면 된다.
fun <T> Collection<T>.joinToString(
separator: String = ", ",
prefix: String = "",
postfix: String = "",
transform: ((T) -> String)? = null
): String {
val result = StringBuilder(prefix)
for ((index, element) in this.withIndex()) {
if (index > 0) result.append(separator)
val str = transform?.invoke(element)
?: element.toString()
result.append(str)
}
result.append(postfix)
return result.toString()
}함수를 함수에서 반환
프로그램의 상태(state)나 컨디션에 매우 의존하고 있는 프로그램을 생각해보면, 함수에서 함수를 반환하는 것이 필요한 경우를 알 수 있다.
fun getShippingCostCalculator(
delivery: Delivery): (Order) -> Double {
if (delivery == Delivery.EXPEDITED) {
return { order -> 6 + 2.1 * order.itemCount }
}
return { order -> 1.2 * order.itemCount }
}위의 코드에서는 delivery에 따라 order에 사용되어야 하는 함수가 다르기 때문에 리턴할 때 서로 다른 함수를 사용하도록 구성하였다. 이렇게 함수의 리턴 타입이 함수라는 것을 명시해주고 싶을 때는 (Order) -> Double와 같이 리턴 타입을 명시해야 한다.
람다를 활용한 중복 제거
코드의 중복을 제거하고 싶을 경우 람다를 사용할 수 있다. 다음과 같은 함수를 람다를 사용해서 중복을 없앨 수 있다.
data class SiteVisit(
val path: String,
val duration: Double,
val os: OS
)
enum class OS { WINDOWS, LINUX, MAC, IOS, ANDROID }
val log = listOf(
SiteVisit("/", 34.0, OS.WINDOWS),
SiteVisit("/", 22.0, OS.MAC),
SiteVisit("/login", 12.0, OS.WINDOWS),
SiteVisit("/signup", 8.0, OS.IOS),
SiteVisit("/", 16.3, OS.ANDROID)
)이를 람다를 사용해서 다음과 같이 바꿀 수 있다.
fun List<SiteVisit>.averageDurationFor(predicate: (SiteVisit) -> Boolean) =
filter(predicate).map(SiteVisit::duration).average()
>>> println(log.averageDurationFor {
... it.os in setOf(OS.ANDROID, OS.IOS) })
12.15
>>> println(log.averageDurationFor {
... it.os == OS.IOS && it.path == "/signup" })
8.0인라인 함수: 람다의 부가 비용 없애기
위에서 보다싶이, 람다를 사용하면 syntax를 짧게 바꿀 수 있다. 그런데 성능은 어떻게 될까? 코드가 더 느리게 동작하는 것이 아닐까? 람다가 변수를 포획하면 람다가 생성되는 시점마다 새로운 무명 클래스 객체가 생성되어 비용 발생한다. 이는 런타임 오버해드를 만들 수 있으며, 람다를 사용하는 방식이 더 비효율적으로 만들 수도 있다.
컴파일러에게 자바 코드와 비슷하게 효율적인 코드를 만들면서도 반복되는 로직을 추출하게 만들 수 있을까? 사실, 코틀린 컴파일러는 이러한 기능을 제공한다. 이를 바로 inline 변경자라고 부른다. inline 변경자가 붙은 함수는 컴파일러가 그 함수를 호출하는 모든 문장을 함수 본문에 해당하는 바이트 코드로 변환한다.
인라이닝이 작동하는 방식
함수를 inline이라고 선언하면, 그것의 본문이 inline된다. 즉 해당 함수의 본문이 호출 위치에 인라인된다고 할 수 있다. 이러한 syntax는 마치 자바에서 synchronized를 사용하는 것과 비슷해보인다. 차이점은 synchronized는 아무 객체에서나 사용될 수 있지만, 인라인은 Lock 인스턴스를 패스할 것을 요구한다는 점이다.
fun foo(l: Lock) {
println("Before sync")
synchronized(l) {
println("Action")
}
println("After sync")
}
이때 람다에서 생성된 바이트코드는 호출하는 함수 정의의 일부분이 된다. 또한, 인라인 함수를 호출하고 함수 타입을 파라미터로 전달하는 것 또한 가능하다. 이 경우에 람다는 인라인 함수가 호출된 곳에 존재하지 않고, 따라서 인라인되지 않는다. synchronized 함수의 본문만이 인라인 될 뿐이다.
class LockOwner(val lock: Lock) {
fun runUnderLock(body: () -> Unit) {
synchronized(lock, body)
}
}인라인 한계
인라인이 작동하는 방식 때문에 람다를 사용하는 함수 중에서도 인라인 될 수 없는 것들이 있다. 인자로 전달된 람다식의 본문은 결과 코드에 직접 들어가기 때문에 방식이 한정적이다.
람다를 다른 변수에 저장 후 나중에 그 변수를 사용하면 람다를 인라인 할 수 없다. 그 이유는 람다를 표현하는 객체가 어딘가는 존재해야 하기 때문이다.
💡 참고: 인라인 제외 함수 파라미터를 인라인에서 제외하려면 noinline 변경자를 붙여 인라이닝 금지시키면 된다.
컬렉션 연산 인라이닝
standard library를 사용하는 것보다 오퍼레이션을 직접 구현하는 것이 더 효율적일까?
/* 람다를 사용한 컬렉션 필터링 */
data class Person(val name: String, val age: Int)
val people = listOf(Person("Alice", 29), Person("Bob", 31))
>>> println(people.filter { it.age < 30 })
[Person(name=Alice, age=29)]코틀린에서 filter 함수는 인라인으로 선언되어 있다. 따라서 filter 함수의 바이트코드는 전달된 람다의 바이트코드와 함께 filter 함수가 호출된 곳에서 인라인된다. 즉, 컬렉션의 연산을 사용해도 코틀린은 인라인 함수를 서포트하여 퍼포먼스를 걱정하지 않아도 된다.
컬렉션의 filter, map 등 함수도 인라인 함수인데, 인라인되므로 중간 리스트를 사용하게 된다. 따라서 부가비용이 발생한다. 원소의 숫자가 많아지면 이러한 중간 리스트는 굉장한 걱정거리가 된다. 이때 asSequence를 사용하면 시퀀스로 사용하여 중간 컬렉션을 생성하지 않을 수 있다.
함수를 인라인으로 선언해야 하는 이유
인라인 함수를 람다 인자와 함께 사용하는 것은 유용하다. 먼저, 인라인을 통해 오버헤드를 무시할 수 있다. 람다 호출 비용 감소하며, 람다를 위한 객체 생성이 감소한다. 둘째, JVM은 함수 호출과 람다를 인라인할 만큼 똑똑하지 못하다. 마지막으로, 인라인을 하면 레귤러 람다를 사용할 수 있는 방법을 제시한다.
한편, 인라이닝은 바이트코드 크기를 증가시키므로 인라인 함수 크기를 작게 만드는 데 관심을 가지고 있어야 한다.
자원 관리를 위해 인라인된 람다 사용
인라인된 람다를 자주 사용하는 부분은 자원 관리를 할 때이다. 정석적으로 이를 위한 방법은 try/finally를 사용하여 자원이 try에서 사용되도록 하고, finally 블록에서 릴리즈 되도록 하는 것이다.
자바에서는 이를 try‐with‐resource와 같은 기능으로도 구현할 수 있지만, 코틀린에서는 이를 지원하지 않는다. 대신 use를 사용하여 구현할 수 있다.
fun readFirstLineFromFile(path: String): String {
BufferedReader(FileReader(path)).**use** { br ‐>
return br.readLine()
}
}use는 람다를 인자로 받으며, 자원이 확실하게 닫혀 있도록 보장한다. 당연하게도 use는 인라인되어 있기 때문에 퍼포먼스 걱정을 하지 않아도 된다.
고차 함수 안에서 흐름 제어
람다 안의 return문: 람다를 둘러싼 함수로부터 반환
fun lookForAlice(people: List<Person>) {
people.forEach { // forEach : 인라인 함수
if (it.name == "Alice") {
println("Found!")
return // lookForAlice 함수에서 리턴
}
}
println("Alice is not found")
}이때 return은 람다로부터만 반환되는 게 아니라 그 람다를 호출하는 함수에 대해 반환하는 것이다. 이렇게 자신을 둘러싸고 있는 블록보다 더 바깥에 있는 다른 블록을 반환하게 만드는 return문을&non-local return이라 하는데, 람다를 인자로 받는 함수가 인라인 함수일 경우에만 가능하다.
람다로부터 반환 : 레이블을 사용한 return
람다식에서 로컬 return을 사용하는 것도 가능하다. 이는 for 루프의 break와 비슷한데, 로컬 return은 람다의 실행을 끝내고 람다를 호출했던 코드 실행을 계속한다. 로컬 return과 로컬이 아닌 return을 구분하기 위해 label이나 함수 이름을 label로 사용한다.
fun lookForAlice(people: List<Person>) {
people.forEach label@{
if (it.name == "Alice") return@label
}
println("Alice might be somewhere")
}
>>> lookForAlice(people)
Alice might be somewhere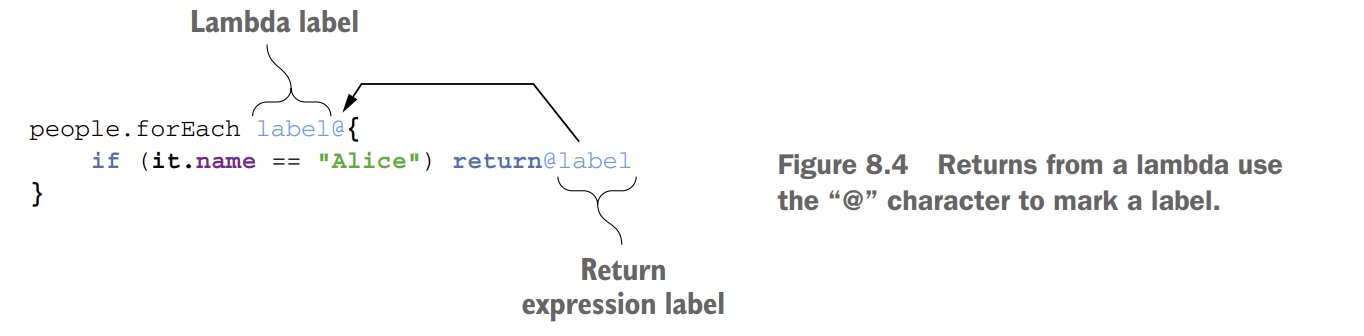
무명 함수 : 기본적으로 로컬 return
아래 코드에서 fun (person) { ... }가 이름이 없기 때문에 무명 함수가 된다. 이때 리턴값은 가장 가까운 fun 키워드를 찾아 정의된 가장 안쪽 함수를 리턴하게 된다.
fun lookForAlice(people: List<Person>) {
people.forEach(fun (person) {
if (it.name == "Alice") return // 가장 가까운 무명 함수에서 리턴
println("${person.name} is not Alice")
})
}Last updated